Kaldi学习笔记
Table of Contents
- 1. kaldi timit脚本解析
- 2. kaldi中的数据文件及其作用
- 3. kaldi doc
- 3.1. kaldi tutorial
- 3.2. Kaldi I/O mechanisms
- 3.3. The Kaldi Matrix library
- 3.4. The build process(how Kaldi is compiled)
- 3.5. Parsing command-line Options
- 3.6. Decoders used in the Kaldi toolkit
- 3.7. HMM topology and transition modeling
- 3.8. How decision trees are used in Kaldi
- 3.9. Decoding-graph creation recipe(training time)
- 3.10. Other kaldi utilities
- 3.11. Clustering mechanisms in Kaldi
- 3.12. Acoustic modeling code
- 3.13. Deep Neural Networks in Kaldi
- 4. kaldi cuda
- 5. kaldi 部分代码解析
- 6. Kaldi Keypoint
- 7. Kaldi二进制文件查看
- 8. fst
- 9. Google C++ Style Guide
1 kaldi timit脚本解析
1.1 keynotes
1. train_cmd在cmd.sh中定义,训练方式选择 2. 所有日志记录文件保存exp目录下 3. utils/parse_option.sh + config参数及文件是否存在 4. ark, archive, data all in one file 5. rspecifier, wspecifier 6. $dir一般输出哈 7. cmd=run.pl 8. timit中仅用到音素级标注.PHN, 并未用到词级.txt
1.2 数据准备
1.2.1 timit_data_prepare.sh
- wav.scp:文件列表
- uttids:文件id
- text:抄本
- utt2spk spk2utt:语音–>说话人
- duration calc, mean, min, max,在别的任务中不是必须的
- stm, gtm等文件,在别的人物中也不是必须的
1.2.2 timit_prepare_dict.sh
- phone
- lm:音素级bigram,build-lm.sh compile-lm
1.2.3 utils/prepare_lang.sh
参数: 1. --position-dependent-phones false, 音素是否设置为与在词中的位置相关 (B)egin, (E)nd, (I)nternal and (S)ingleton,设置相关后,单个音素会扩展为4个。 a_B 6 a_E 7 a_I 8 a_S 9 2. "sil" "!SIL" "<UNK>" 写入到oov.txt
- sets.txt音素 sets.int 整数
- roots.txt "shared split aa" roots.int
- silence.txt nonsilence.txt context_indep.txt extra_questions.txt
- disambig.txt: 辅助符号
- phones.txt(silence.txt nosilence.txt disambig.txt)
- words.txt(esp 0, #0) phones.txt(增加silence和#0,#1)
- align_lexicon.txt
- fstcompile –isymbols=$dir/phones.txt –osymbols=$dir/words.txt
- 为什么构造这样一个L.fst 0.693147180559945(log 0.5)
1.2.4 timit_format_data.sh
- 将data lang数据分类归整到data\train test文件夹下,标准命令,例如原train.text修改为data/train/text文件
- utils/validate_data_dir.sh –no-feats data/$x || exit 1, 这个很重要,检查数据准备是否有序,kaldi中要求有序,便于随机读取
- 准备了G.fst
1.3 特征提取
1.3.1 make_mfcc.sh
- conf/mfcc.conf: –user-energy=false
- .parse_option.sh 得看看
- 分割scp题特征,并行提特征ark,再连接特征列表至feats.scp
- log文件夹exp
1.3.2 compute_cmvn_stats.sh
- 生成文件目录同mfcc
- cmvn使用到spk2utt,做什么用?
- cmvn是对每一个说话人做的
- compute-cmvn-stats: ????
1.4 MonoPhone Training & Decoding
1.4.1 steps/train_mono.sh
- totgauss=1000
- compile-train-graphs
- stage=-4, |-3|-2|-1
- feat-to-dim: 获得特征维度39
- gmm-init-mono 输出模型0.mdl和tree单音素树
- 计算特征全局均值方差
- 所有单音素表示成为一棵树
- data/lang/topo 初始hmm模型参数, left-right-hmm
- compile-train-graph 为每个训练语句构造一个解码的fst
- align-equal-compiled:对特征等分对齐进行初始化
- gmm-est: 根据对齐结果对模型进行更新,每个状态的高斯数不等
10.gmm-align-compiled: 在fst上识别,输出对齐
- loop: gmm-align-compiled gmm-acc-stats-ali gmm-est
- add-deltas, 使用2阶和3阶差分mfcc,此时39
- compute-cmvn-stats计算cmvn, apply-cmvn对特征文件使用cmvn
1.4.2 utils/mkgraph.sh
1.4.3 steps/decode.sh
- feat_type: lda | delta
- mono input: exp/mono/graph(model) data/dev(source)
- gmm-latgen-faster:解码
- local/score.sh
- JOB=1:$nj
- output:lat.n.gz
1.5 tri1: Deltas + Delta-Deltas Training & Decoding
1.5.1 steps/align_si.sh
- output: mono_ali
- gmm-align-complied
- compile-train-graphs
1.5.2 steps/train_deltas.sh
- acc-tree-stats
SplitToPhones() end_points: 检测一个状态结束位置 AccumulateTreeStats 输出map<EventType, ClusterableInterface>, 假设为单音素<{(-1,66), (0, 22)}, I>的map结构 ClusterableInterface保存特征个数,并提供Add方法对特征进行累加,可以计算均值和方差。
- sum-tree-stats: 统计三音素上下文特征
- cluster-phones:根据单音素聚类,生成所有可能的问题集, TreeCluster & KMeans
- compile-questions:生成qst文件,为EventType设置问题集,key=-1问题集为[0 ] [0 1], key=0, 1, 2问题集为questions.txt
- build-tree: 建立决策树
- gmm-init-model
- gmm-mixup
1.6 tri2 : LDA + MLLT Training & Decoding
1.6.1 steps/train_lda_mllt.sh
- 拼接特征 splice-feats, 前后7帧
- weight-silence-post: 将post中silence的weight*silence_weight = 0.0
silence_scale=0.0 void WeightSilencePost(const TransitionModel &trans_model, const ConstIntegerSet<int32> &silence_set, BaseFloat silence_scale, Posterior *post) { for (size_t i = 0; i < post->size(); i++) { std::vector<std::pair<int32, BaseFloat> > this_post; this_post.reserve((*post)[i].size()); for (size_t j = 0; j < (*post)[i].size(); j++) { int32 tid = (*post)[i][j].first, phone = trans_model.TransitionIdToPhone(tid); BaseFloat weight = (*post)[i][j].second; if (silence_set.count(phone) != 0) { // is a silence. if (silence_scale != 0.0) this_post.push_back(std::make_pair(tid, weight*silence_scale)); } else { this_post.push_back(std::make_pair(tid, weight)); } } (*post)[i].swap(this_post); } }
- acc-lda: 按照pdf id进行统计
Posterior pdf_post; ConvertPosteriorToPdfs(trans_model, post, &pdf_post); for (int32 i = 0; i < feats.NumRows(); i++) { SubVector<BaseFloat> feat(feats, i); for (size_t j = 0; j < pdf_post[i].size(); j++) { int32 pdf_id = pdf_post[i][j].first; BaseFloat weight = RandPrune(pdf_post[i][j].second, rand_prune); if (weight != 0.0) { lda.Accumulate(feat, pdf_id, weight); } } }
- est_lda
- dim=40
void LdaEstimate::Estimate(const LdaEstimateOptions &opts, Matrix<BaseFloat> *m, Matrix<BaseFloat> *mfull) const { int32 target_dim = opts.dim; KALDI_ASSERT(target_dim > 0); // between-class covar is of most rank C-1 KALDI_ASSERT(target_dim <= Dim() && (target_dim < NumClasses() || opts.allow_large_dim)); int32 dim = Dim(); double count; SpMatrix<double> total_covar, bc_covar; Vector<double> total_mean; GetStats(&total_covar, &bc_covar, &total_mean, &count); // within-class covariance SpMatrix<double> wc_covar(total_covar); wc_covar.AddSp(-1.0, bc_covar); TpMatrix<double> wc_covar_sqrt(dim); try { wc_covar_sqrt.Cholesky(wc_covar); } catch (...) { BaseFloat smooth = 1.0e-03 * wc_covar.Trace() / wc_covar.NumRows(); KALDI_LOG << "Cholesky failed (possibly not +ve definite), so adding " << smooth << " to diagonal and trying again.\n"; for (int32 i = 0; i < wc_covar.NumRows(); i++) wc_covar(i, i) += smooth; wc_covar_sqrt.Cholesky(wc_covar); } Matrix<double> wc_covar_sqrt_mat(wc_covar_sqrt); // copy wc_covar_sqrt to Matrix, because it facilitates further use wc_covar_sqrt_mat.Invert(); SpMatrix<double> tmp_sp(dim); tmp_sp.AddMat2Sp(1.0, wc_covar_sqrt_mat, kNoTrans, bc_covar, 0.0); Matrix<double> tmp_mat(tmp_sp); Matrix<double> svd_u(dim, dim), svd_vt(dim, dim); Vector<double> svd_d(dim); tmp_mat.Svd(&svd_d, &svd_u, &svd_vt); SortSvd(&svd_d, &svd_u); KALDI_LOG << "Data count is " << count; KALDI_LOG << "LDA singular values are " << svd_d; KALDI_LOG << "Sum of all singular values is " << svd_d.Sum(); KALDI_LOG << "Sum of selected singular values is " << SubVector<double>(svd_d, 0, target_dim).Sum(); Matrix<double> lda_mat(dim, dim); lda_mat.AddMatMat(1.0, svd_u, kTrans, wc_covar_sqrt_mat, kNoTrans, 0.0); // finally, copy first target_dim rows to m m->Resize(target_dim, dim); m->CopyFromMat(lda_mat.Range(0, target_dim, 0, dim)); if (mfull != NULL) { mfull->Resize(dim, dim); mfull->CopyFromMat(lda_mat); } if (opts.within_class_factor != 1.0) { // This is not the normal code path; // it's intended for use in neural net inputs. for (int32 i = 0; i < svd_d.Dim(); i++) { BaseFloat old_var = 1.0 + svd_d(i), // the total variance of that dim.. new_var = opts.within_class_factor + svd_d(i), // the variance we want.. scale = sqrt(new_var / old_var); if (i < m->NumRows()) m->Row(i).Scale(scale); if (mfull != NULL) mfull->Row(i).Scale(scale); } } if (opts.remove_offset) { AddMeanOffset(total_mean, m); if (mfull != NULL) AddMeanOffset(total_mean, mfull); } }
1.7 karel's dnn
1.7.1 feature
#zss splice feature feats_cv="ark,s,cs:utils/filter_scp.pl $dir/valid_uttlist $data/feats.scp | apply-cmvn --norm-vars=$norm_vars $data/norm_global_mv.ark scp:- ark:- | splice-feats ark:- ark:-|" #dnn Generate the splice transform echo "Using splice +/- $splice , step $splice_step" feature_transform=$dir/tr_splice$splice-$splice_step.nnet utils/nnet/gen_splice.py --fea-dim=$feat_dim --splice=$splice --splice-step=$splice_step > $feature_transform
1.8 DNN Hybrid Training & Decoding
1.8.1 网络结构(输入、输出、隐层)
- num_epochs=15, numjobs_nnet = 16, hidden_layer_dim=300, minibatch_size=128, shuffle_buffer_size
- num_hidden_layers=3
- 输入特征 lda, feat, get_lda, (egs空暂不考虑)
- 输出的是什么 num_leaves,状态
- nnet.config
- hidden.config
1.8.2 get_lda.sh
- 输出lda.mat
1.8.3 get_egs.sh
- transform_dir=$alidir
- shuffle_list, 随机从训练语句中抽取300
awk '{print $1}' $data/utt2spk | utils/shuffle_list.pl | head -$num_utts_subset \
> $dir/valid_uttlist || exit 1;
- valid_uttlist, train_subset_uttlist 两个互补
- samples_per_iter
- num_frame: 1124823, samples_per_iter: 200000
- nnet-get-egs: 准备网络输入格式的数据,上下文特征,pdf标签
1.8.4 训练
- 问题
- 数据结构
- Example
struct NnetExample { /// The label(s) for this frame; in the normal case, this will be a vector of /// length one, containing (the pdf-id, 1.0) std::vector<std::pair<int32, BaseFloat> > labels; /// The input data-- typically with NumRows() more than /// labels.size(), it includes features to the left and /// right as needed for the temporal context of the network. /// (see the left_context variable). CompressedMatrix input_frames; /// The number of frames of left context (we can work out the #frames /// of right context from input_frames.NumRows(), labels.size(), and this). int32 left_context; /// The speaker-specific input, if any, or an empty vector if /// we're not using this features. We'll append this to each of the Vector<BaseFloat> spk_info; /// Set the label of this example to the specified pdf_id /// with the specified weight. void SetLabelSingle(int32 pdf_id, BaseFloat weight = 1.0); /// Get the maximum weight label (pdf_id and weight) of this example. int32 GetLabelSingle(BaseFloat *weight = NULL); };
- Component
// nnet/nnet-activation.h class Softmax : public Component class BlockSoftmax : public Component class Sigmoid : public Component class Tanh : public Component class Dropout : public Component
- NnetSimpleTrainer
//里面没有prior_的信息, 那么prior在那里用? void NnetSimpleTrainer::TrainOnExample(const NnetExample &value) { buffer_.push_back(value); if (static_cast<int32>(buffer_.size()) == config_.minibatch_size) TrainOneMinibatch(); } void NnetSimpleTrainer::TrainOneMinibatch() { KALDI_ASSERT(!buffer_.empty()); // The following function is declared in nnet-update.h. logprob_this_phase_ += DoBackprop(*nnet_, buffer_, nnet_); weight_this_phase_ += TotalNnetTrainingWeight(buffer_); buffer_.clear(); minibatches_seen_this_phase_++; if (minibatches_seen_this_phase_ == config_.minibatches_per_phase) { bool first_time = false; BeginNewPhase(first_time); } }
- AmNnet
//Amnet class AmNnet { Nnet nnet_; Vector<BaseFloat> priors_; };
- 训练工具
- nnet-init: Initialize the neural network from a config file with a line for each component
- nnet-am-init: 好像只把nnet,tree, topo写到一个文件了
- nnet-get-egs: 生成examples(准备网络输入格式的数据,上下文特征,pdf标签)
ProcessFile(feats, pdf_post, key, left_context, right_context, const_feat_dim, keep_proportion, &num_frames_written, &example_writer) for (int32 i = 0; i < feats.NumRows(); i++) { int32 count = GetCount(keep_proportion); // number of times // we'll write this out (1 by default). if (count > 0) { // Set up "input_frames". for (int32 j = -left_context; j <= right_context; j++) { int32 j2 = j + i; if (j2 < 0) j2 = 0; if (j2 >= feats.NumRows()) j2 = feats.NumRows() - 1; SubVector<BaseFloat> src(feats.Row(j2), 0, basic_feat_dim), dest(input_frames, j + left_context); dest.CopyFromVec(src); } eg.labels = pdf_post[i]; eg.input_frames = input_frames; if (const_feat_dim > 0) { // we'll normally reach here if we're using online-estimated iVectors. SubVector<BaseFloat> const_part(feats.Row(i), basic_feat_dim, const_feat_dim); eg.spk_info.CopyFromVec(const_part); } std::ostringstream os; os << utt_id << "-" << i; std::string key = os.str(); // key is <utt_id>-<frame_id> for (int32 c = 0; c < count; c++) example_writer->Write(key, eg); } }
- nnet-shuffle-egs: from the input to output, but randomly shuffle the order
- nnet-subset-egs: Creates a random subset of the input examples, of a specified size
- nnet-train-transitions
void SetPriors(const TransitionModel &tmodel, const Vector<double> &transition_accs, double prior_floor, AmNnet *am_nnet) { KALDI_ASSERT(tmodel.NumPdfs() == am_nnet->NumPdfs()); Vector<BaseFloat> pdf_counts(tmodel.NumPdfs()); KALDI_ASSERT(transition_accs(0) == 0.0); // There is // no zero transition-id. for (int32 tid = 1; tid < transition_accs.Dim(); tid++) { int32 pdf = tmodel.TransitionIdToPdf(tid); pdf_counts(pdf) += transition_accs(tid); } BaseFloat sum = pdf_counts.Sum(); KALDI_ASSERT(sum != 0.0); KALDI_ASSERT(prior_floor > 0.0 && prior_floor < 1.0); //归一化 pdf_counts.Scale(1.0 / sum); pdf_counts.ApplyFloor(prior_floor); pdf_counts.Scale(1.0 / pdf_counts.Sum()); // normalize again. am_nnet->SetPriors(pdf_counts); }
- nnet-train-simple
//默认minibatch(1024),达到minibatch-size时处理 NnetSimpleTrainer trainer(train_config,&(am_nnet.GetNnet())); SequentialNnetExampleReader example_reader(examples_rspecifier); for (; !example_reader.Done(); example_reader.Next(), num_examples++) trainer.TrainOnExample(example_reader.Value()); // It all happens here!
- nnet-train-parallel
- 解码
1.9 Getting Results
运行RESULTS文件, RESULTS中含有统计识别率脚本和标准测试结果
2 kaldi中的数据文件及其作用
2.1 数据准备(其中大部分文件均需要排序)
2.1.1 Required(Must provide)
在数据准备过程中,必须准备并在以后训练过程中必须存在的有以下文件,注意啦
- train.uttid test.uttid (data/local/data)
作用: 文件唯一标识符 格式: FAEM0_SI1392 FAEM0_SI2022
- train_wav.scp test_wav.scp dev_wav.scp(data/local/data)
作用: 数据文件列表 格式: FBMJ0_SI815 /home/robin1001/kaldi/kaldi-trunk/egs/timit/s5/../../../tools/sph2pipe_v2.5/sph2pipe -f wav /home/robin1001/data/timit/TIMIT/TRAIN/DR4/FBMJ0/SI815.WAV |
- train.text test.text dev.text(data/local/data)
作用: 抄本, 注意sil扩展 格式: FAEM0_SI1392 sil ax s uw m f ao r ix vcl z ae m cl p uh l ax s n vcl d f iy l vcl s sil
- train.utt2spk train.spk2utt(data/local/data)
作用: 说话人信息到uttid 使用: 1. 计算cmvn时, compute-cmvn-stats使用spk2uut 格式: utt2spk: FAEM0 FAEM0_SI1392 FAEM0_SI2022 FAEM0_SI762 FAEM0_SX132 FAEM0_SX222 FAEM0_SX312 FAEM0_SX402 FAEM0_SX42 spk2utt: FAEM0_SI1392 FAEM0
以上内容在format_data时会被分类整理在data/train, data/test, data/dev目录下,整理时名称可能会有改变
2.1.2 Timit Required
以下文件timit也准备了,对于其他任务不一定必须,在此仅列出
- train.spk2gender(data/local/data)
作用: 说话人到性别信息 使用: 没有看到 格式: FAEM0 f FAJW0 f
- train_dur.ark(data/local/data)
作用: 训练数据时长信息 使用: 没有看到 格式: FAEM0_SI1392 4.761625 FAEM0_SI2022 2.252812
- train.stm(data/local/data)
作用: 扩展形式的超本,加入说话人,性别,时长信息 使用: stm和gtm这玩意儿timit独有,和解码时还有关系 格式: ;; LABEL "O" "Overall" "Overall" ;; LABEL "F" "Female" "Female speakers" ;; LABEL "M" "Male" "Male speakers" FAEM0_SI1392 1 FAEM0 0.0 4.761625 <O,M> sil ax s uw m f ae n vcl d f iy l vcl s sil
- train.glm(data/local/data)
作用: 这是啥? 格式: 所有内容都在这儿 ;; empty.glm [FAKE] => %HESITATION / [ ] __ [ ] ;; hesitation token
2.2 字典准备
- silence_phones.txt nonsilence_phones.txt(data/local/dict)
作用: 静音音素和非静音音素,两个互斥的集合 格式: sil ---------------- aa bb
- phones.txt(data/local/dict)
使用: silence_phones.txt (U) nonsilence_phones.txt 格式: aa ae ... sil ... zh
- optinal_silence.txt
作用: 可选静音列表,在发音字典fst中,可选的让该phone出现在每段发音段首或者词尾
根据任务而定,可选的sil, spn
格式:
sil
----------------
aa
bb
- lexicon.txt(data/local/dict)
作用: 词典 格式: 此处因为timit是音素级的抄本,所以lexicon长这样 aa aa ae ae ah ah ---------------- 阿爸 a1 ba4
- extra_questions.txt(data/local/dict)
作用: 初始的问题集,分为sil和其他两类 使用: cat $lang/phones/extra_questions.int >> $dir/questions.int 格式: sil aa ae ah ao aw ax ay b ch cl d dh dx eh el en epi er ey f g hh ih ix iy jh k l m n ng ow oy p r s sh t th uh uw v vcl w y z zh
- lm_train.text(data/local/data)
作用: 格式化抄本,添加语言模型的<s>&</s> 格式: <s> sil w ah dx aw f ix cl d uh sh iy vcl d r ay v f ao sil </s> <s> sil f ih l s epi m ao l hh ow l ix n vcl b ow l w ih th cl k l ey sil </s> 使用: 去除uutid,作为build-lm.sh输入
- lm_phone_bg.arpa.gz(data/local/nist_lm)
作用:编译并压缩后的语言模型 格式: \data\ ngram 1= 51 ngram 2= 1694 \1-grams: -4.8574 <s> -2.96614 -1.24019 sil -2.27704 -1.56815 ax -2.02608 ... \2-grams: -0.000442966 <s> sil -3.37261 sil sil -1.83346 sil ax -1.62848 sil s -3.71728 sil uw 使用: format_data生成G.fst
2.3 lang(此处有个中间文件utils/apply_map.pl phone_map)
- sets.txt sets.int(data/lang/phones)
使用: 1. shared_phones_opt=set.int, gmm-init-mono 格式: sil aa ... ------------ 1 2 ...
- root.txt (data/lang/phones)
作用: 哪些音素共享根 格式: shared split sil shared split aa shared split ae ----------------- shared split 1 shared split 2 shared split 3
- oov.txt oov.int(data/lang)
作用: 将词汇表以外词映射到该词,所以其在也仅在compile-train-graphs作为输入 格式: sil ------------ 38
- silence.txt,nonsilence.txt, silence.int, nonsilence.int(data/lang/phones)
作用: 格式: 估计你都猜到了,不粘了 silence.csl 1 nonsilencs.csl 2:3:4:5:6:7:8:9:10:11:12:13:14:15:16:17:18:19:20:21:22:23:24:25:26:27:28:29:30:31:32:33:34:35:36:37:38:39:40:41:42:43:44:45:46:47:48
- disambig.txt(data/lang/phones)
作用: fst的两个辅助消歧符号 格式: #0 #1
- phones.txt(data/lang/phones.txt)
作用: openfst形式isymbol-map 格式: <eps> 0 sil 1 aa 2 ae 3 ... #0 49 #1 50
- word_boundary.txt(没有用到)
- words.txt
作用: openfst形式isymbol-map 使用: 解码时--word-symbol-table=words.txt 格式: <eps> 0 aa 1 ae 2 ah 3 ... #0 49
- context_indep.txt
包含一个音素列表,用于建立文本无关模型,即不会建立上下文决策树。 一般有静音SIL,口语噪音SPN,非口语噪音NSN,笑声LAU 经验:把噪声和发声噪声都列为静音音素,而把其他传统音素列为非静音因素
- lexiconp.txt(data/local/dict)
作用: 格式: aa 1.0 aa ae 1.0 ae ah 1.0 ah
- L.fst L.disambig.fst(data/lang)
utils/make_lexicon_fst.pl --pron-probs $tmpdir/lexiconp.txt $sil_prob $silphone | \ fstcompile --isymbols=$dir/phones.txt --osymbols=$dir/words.txt \ --keep_isymbols=false --keep_osymbols=false | \ fstarcsort --sort_type=olabel > $dir/L.fst || exit 1;
使用: 1. compile-train-graph,为训练语句编译fst, 如exp/x/fsts.JOB.gz
2. 解码时生成HCLG.fst, 使用的是L.disambig.fst
fst状态转换
0 1 <eps> <eps> 0.693147180559945
0 1 sil <eps> 0.693147180559945
2 1 sil <eps>
1 1 aa aa 0.693147180559945
1 2 aa aa 0.693147180559945
1 1 ae ae 0.693147180559945
1 2 ae ae 0.693147180559945
1 1 ah ah 0.693147180559945
1 2 ah ah 0.693147180559945
1 1 ao ao 0.693147180559945
1 2 ao ao 0.693147180559945
1 1 aw aw 0.693147180559945
1 2 aw aw 0.693147180559945
1 1 ax ax 0.693147180559945
1 2 ax ax 0.693147180559945
1 1 ay ay 0.693147180559945
1 2 ay ay 0.693147180559945
1 1 b b 0.693147180559945
...
1 1 zh zh 0.693147180559945
1 2 zh zh 0.693147180559945
1 0
- topo(data/lang)
作用: HMM集合及其拓扑结构
使用: 1. 训练过程中模型的初始化,如gmm-init-mono
2. 获取问题集compile-questions
格式:
<Topology>
<TopologyEntry>
<ForPhones>
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
</ForPhones>
<State> 0 <PdfClass> 0 <Transition> 0 0.75 <Transition> 1 0.25 </State>
<State> 1 <PdfClass> 1 <Transition> 1 0.75 <Transition> 2 0.25 </State>
<State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State>
<State> 3 </State>
</TopologyEntry>
<TopologyEntry>
<ForPhones>
1
</ForPhones>
<State> 0 <PdfClass> 0 <Transition> 0 0.5 <Transition> 1 0.5 </State>
<State> 1 <PdfClass> 1 <Transition> 1 0.5 <Transition> 2 0.5 </State>
<State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State>
<State> 3 </State>
</TopologyEntry>
</Topology>
2.4 format_data
- format
| id | src | dest |
| 1 | train_wav.scp | train/wav.scp |
| 2 | train.text | train/text |
| 3 | train.spk2utt | train/spk2uut |
| 4 | train.spk2gen | train/spk2gender |
| 5 | train.stm | train/stm |
| 6 | train.glm | train/glm |
- G.fst
格式: 0 1 <s> <s> 1 2 <eps> <eps> 6.82978964 1 3 sil sil 0.00101996691 2 3 sil sil 2.85564303 2 4 ax ax 3.61079884 2 5 s s 3.14913034 2 6 uw uw 4.3006072 2 7 m m 3.69825077 2 8 f f 4.17426443 2 9 ao ao 4.34617519 2 10 r r 3.42624664 2 11 ix ix 2.97240686 2 12 vcl vcl 2.99313045 2 13 z z 3.66624475 2 14 ae ae 4.14011717 2 15 cl cl 2.44272041 2 16 p p 4.01870155
2.5 特征提取
- raw_mfcc_train.1.scp raw_mfcc_train.1.ark(mfcc)
格式: scp FADG0_SI1279 /home/robin1001/kaldi/kaldi-trunk/egs/timit/s5/mfcc/raw_mfcc_dev.1.ark:13 FADG0_SI1909 /home/robin1001/kaldi/kaldi-trunk/egs/timit/s5/mfcc/raw_mfcc_dev.1.ark:2491
- feats.scp(data/{train, test, dev})
作用: 由并行提到特征文件合成所有的特征列表
- cmvn_train.scp cmvn_train.ark
compute-cmvn-stats --spk2utt=ark:$data/spk2utt scp:$data/feats.scp ark,scp:$cmvndir/cmvn_$name.ark,$cmvndir/cmvn_$name.scp
作用: 统计每个说话人的cmvn信息 格式: FAPB0 /home/robin1001/kaldi/kaldi-trunk/egs/timit/s5/mfcc/cmvn_train.ark:986 FBAS0 /home/robin1001/kaldi/kaldi-trunk/egs/timit/s5/mfcc/cmvn_train.ark:1231
2.6 决策树
- question.int question.txt
sil sil b ch cl d dh dx epi f g hh jh k p s sh t th v vcl z zh sil ch f s sh z aa aa ae ah ao aw ax ay eh el en er ey ih ix iy l m n ng ow oy r uh uw w y aa ae ao aw ay eh ey ih iy ow y aa ae ao aw ay ow aa ao aa ao ow ae ae aw ae aw ay ah ah ax el en er ix l m n ng oy r uh uw w ah ax er ix oy r uh uw ah ax ix uh ah ax ix uh uw ah ax uh
2.7 训练
- x.mdl find.mdl(exp/x/)
格式: <TransitionModel> <Topology> <TopologyEntry> <ForPhones> 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 </ForPhones> <State> 0 <PdfClass> 0 <Transition> 0 0.75 <Transition> 1 0.25 </State> <State> 1 <PdfClass> 1 <Transition> 1 0.75 <Transition> 2 0.25 </State> <State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State> <State> 3 </State> </TopologyEntry> <TopologyEntry> <ForPhones> 1 </ForPhones> <State> 0 <PdfClass> 0 <Transition> 0 0.5 <Transition> 1 0.5 </State> <State> 1 <PdfClass> 1 <Transition> 1 0.5 <Transition> 2 0.5 </State> <State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State> <State> 3 </State> </TopologyEntry> </Topology> <Triples> 1967 1 0 0 1 1 51 1 2 48 2 0 1 2 0 169 2 0 286 ... </LogProbs> </TransitionModel> <DIMENSION> 39 <NUMPDFS> 1921 <DiagGMM> <GCONSTS> [ -95.17706 -81.32135 -151.1496 -92.49072 -76.49657 -73.69149 -125.8088 -83.51283 -104.7302 -87.7104 -85.27476 -84.29331 -74.78059 -115.8744 -80.226 36 -93.32332 -95.39783 -128.1057 -80.69289 -94.86904 -77.14107 -125.0487 -85.18453 -80.24683 -80.09453 -115.6893 ] <WEIGHTS> [ 0.0376287 0.03753155 0.03834436 0.04315818 0.05027013 0.04145537 0.03278675 0.04632599 0.04273623 0.03133279 0.04082224 0.04645732 0.03122336 0.02 904686 0.03832259 0.04545283 0.04021866 0.041621 0.04777169 0.03450852 0.04088681 0.03478571 0.03945986 0.03233045 0.0284235 0.02709854 ] <MEANS_INVVARS> [ -0.2801608 -0.07388612 0.05452524 -0.0001664911 0.1077678 0.09175234 0.08498141 0.09413936 0.020672 0.02511335 0.006077958 -0.0216168 0.008959025 -0.5031475 -0.41583 -0.2404581 -0.1 ...
- tree(exp/x)
作用: 三音素决策树
格式:
ContextDependency 3 1 ToPdf TE 1 49 ( NULL SE -1 [ 0 1 ]
{ SE -1 [ 0 ]
{ CE 0 CE 51 }
CE 48 }
SE -1 [ 0 ]
{ SE 0 [ 1 9 10 11 12 13 14 18 21 22 23 27 28 35 37 38 39 40 43 44 47 48 ]
{ SE 0 [ 1 ]
{ CE 1 SE 2 [ 19 34 36 ]
{ SE 0 [ 21 ]
{ CE 1268 SE 0 [ 9 12 13 23 35 ]
{ SE 0 [ 9 12 13 ]
- exp/x/fsts.JOB.gz
作用: 为每个训练语句由L.fst编译fst
- exp/x/i.JOB.acc
作用: 对齐信息 格式: trn_adg04_sr249 285 283 283 283 283 283 283 283 283 291 292 292 292 292 292 292 290 300 299 266 265 265 265 268 267 270 269 269 269 14 16 18 230 229 232 231 234 146 145 145 145 148 147 150 149 149 149 149 149 104 103 106 108 107 107 107 194 196 195 195 198 197 32 31 34 33 36 35 44 43 43 43 46 45 48 128 130 129 129 132
3 kaldi doc
这里主要是kaldi官网上的重点摘记。
3.1 kaldi tutorial
3.1.1 Reading and modifying the code
- kaldi中使用-O0,调试可以使用gdb调试
- 可以在Makefile TESTFILES中添加自己的test,然后make test
3.2 Kaldi I/O mechanisms
- binary vs text: binary start '\0B'
- ark,t: t in text format
3.3 The Kaldi Matrix library
kaldi的Matrix库为BLAS & LAPACK线性代数库的包装。
3.3.1 Matrix & Vector
Vector<float> v(10), w(9); for(int i=0; i < 9; i++) { v(i) = i; w(i) = i+1; } Matrix<float> M(10,9); M.AddVecVec(1.0, v, w); //A = beta * A + alpha * B * C; B,C是否转置由kNoTrans和kTrans决定 A.AddMatMat(alpha, B, kNoTrans, C, kTrans, beta);
3.3.2 Sub-vectors & Sub-matrices
子向量和矩阵,类似matlab或python中的矩阵切片, SubVector和SubMatrix不能Resize。
Vector<float> v(10), w(10); Matrix<float> M(10, 10); SubVector<float> vs(v, 1, 9), ws(w, 1, 9); SubMatrix<float> Ms(M, 1, 9, 1, 9); // next line would be v(2:10) += M(2:10,2:10)*w(2:10) in some // matrix multiply & add vs.AddMatVec(1.0, Ms, kNoTrans, ws); vs = 1.0 * Ms * ws //切片操作 SubVector row_of_m(M, 0); // M.Row(3), return SubVector // get a sub-vector of length 5 starting from position 0; zero it. v.Range(0, 5).SetZero(); // get a sub-matrix of size 2x2 starting from position (5,5); zero it. M.Range(5, 2, 5, 2).SetZero();
3.3.3 Copy
The simplest ones are the CopyFrom functions, for instance Matrix::CopyFromMat, Vector::CopyFromVec.
3.4 The build process(how Kaldi is compiled)
3.4.1 kaldi.mk
- 默认编译选项:-g -O0 -DKALDI_PARANOID
3.4.2 Makefile
- make test
3.5 Parsing command-line Options
3.5.1 parse-option(util, ParseOption类)
- Read()
3.6 Decoders used in the Kaldi toolkit
详见kaldi部分代码解析之解码。
3.7 HMM topology and transition modeling
3.7.1 HMM topology
<Topology> <TopologyEntry> <ForPhones> 1 2 3 4 5 6 7 8 </ForPhones> <State> 0 <PdfClass> 0 <Transition> 0 0.5 <Transition> 1 0.5 </State> <State> 1 <PdfClass> 1 <Transition> 1 0.5 <Transition> 2 0.5 </State> <State> 2 <PdfClass> 2 <Transition> 2 0.5 <Transition> 3 0.5 </State> <State> 3 </State> </TopologyEntry> </Topology>
- pdfclass index
- 状态3无pdf
- code
struct HmmState { int32 pdf_class; std::vector<std::pair<int32, BaseFloat> > transitions; }; typedef std::vector<HmmState> TopologyEntry; class HmmTopology{ std::vector<int32> phones_; // 排序的音素topo集合 std::vector<int32> phone2idx_; // 音素到hmm topo结构的映射 std::vector<TopologyEntry> entries_; //topo };
3.7.2 Pdf-classes
3.7.3 Transition models (the TransitionModel object)
// (phone, HMM-state, pdf-id) -> transition-state // (transition-state, transition-index) -> transition-id The most "natural" FST-based setups would have what we call pdf-ids on the input labels. However, bearing in mind that given our tree-building algorithms it will not always be possible to map uniquely from a pdf-id to a phone, this would make it hard to map from an input-label sequence to a phone sequence, and this is inconvenient for a number of reasons; it would also make it hard in general to train the transition probabilities using the information in the FST alone. For this reason we put identifiers called transition-ids on the input labels of the FST, and these can be mapped to the pdf-id but also to the phone and to a particular transition in a prototype HMM (as given in the HmmTopology object).
why???
- 将HMM和GMMS(am-diag-gmm)连接起来
- The most "natural" FST-based setups would have what we call pdf-ids on the input labels.
3.8 How decision trees are used in Kaldi
we have a number of ways we can split the data by asking about, say, the left phone, the right phone, the central phone, the state we're in, and so on.
| Name in code | Name in command-line arguments | Value (triphone) | Value (monophone) |
| N | –context-width=? | 3 | 1 |
| P | –central-position=? | 1 | 0 |
vector<int32> ctx_window = { 12, 15, 21 }; 三音素树 12-15+21, 0代表没有音素
kPdfClass=-1,一个音素生成TableEventMap(kPdfClass, map)
一个音素的所有状态生成一个table,每个状态生成一个ConstEventMap,id作为key
3.9 Decoding-graph creation recipe(training time)
compile-train-graphs: 为每个语句训练一个wfst,即H*C*L*G,其中G为根据每条语句 生成的一个acceptor,利用这个fst在这个语句mfcc特征上进行解码,然后反向得到对齐 信息。 gmm-align-compiled: 具体步骤可参考:Internals of graph creation
3.10 Other kaldi utilities
3.10.1 hash-list(util/hash-list.h)
3.10.2 kaldi-table(util/kaldi-table)
实现w和r的参数解析 make valgrind
3.11 Clustering mechanisms in Kaldi
- Clusterable接口
- Clustering algorithms
3.12 Acoustic modeling code
- DiagGmmNormal
- DiagGmm 一个对角混合高斯模型
Vector<BaseFloat> weights_; ///< weights (not log). Matrix<BaseFloat> inv_vars_; ///< Inverted (diagonal) variances Matrix<BaseFloat> means_invvars_; ///< Means times inverted variance
Merge & MergeKMeans ???
- AmDiagGmm
- std::vector<DiagGmm*> densities_;
- num_pdfs个混合高斯模型
- pdf_index混合高斯索引
- LogLikelihood(pdf_index): 返回某个高斯的对数似然
- You can think of AmDiagGmm as a vector of type DiagGmm
- FullGmm: Full-covariance GMMs
- AmSgmm: Subspace Gaussian Mixture Models (SGMMs)
3.13 Deep Neural Networks in Kaldi
3.13.1 两种不同实现
- Karel's:效果好,不并行,使用预训练和交叉验证集。
- Dan's: 并行,无预训练,使用固定训练轮数
4 kaldi cuda
- 是否使用cuda编译
ldd nnet2bin/nnet-train-simple | grep cu
- nnet2使用cuda
steps/nnet2/train_tanh.sh --num-threads 1 --parallel-opts "-l gpu=1"
- 训练时间统计
| cpu/gpu | time |
| nnet2 cpu 16 thread | 45m |
| nnet2 gpu 1 | 81m |
5 kaldi 部分代码解析
5.1 解码
5.1.1 DecodableInterface
virtual BaseFloat LogLikelihood(int32 frame, int32 index); virtual bool IsLastFrame(int32 frame); virtual int32 NumIndices();
5.1.2 SimpleDecoder
class Token { public: Arc arc_; Token *prev_; int32 ref_count_; Weight weight_; ... }; bool LatticeFasterDecoder::Decode(DecodableInterface *decodable) { for(int32 frame = 0; !decodable.IsLastFrame(frame-1); frame++) { ClearToks(prev_toks_); std::swap(cur_toks_, prev_toks_); ProcessEmitting(decodable, frame); ProcessNonemitting(); PruneToks(cur_toks_, beam_); } } // Outputs an FST corresponding to the raw, state-level // tracebacks. bool LatticeFasterDecoder::GetRawLattice(fst::MutableFst<LatticeArc> *ofst) const { typedef LatticeArc Arc; typedef Arc::StateId StateId; typedef Arc::Weight Weight; typedef Arc::Label Label; ofst->DeleteStates(); // num-frames plus one (since frames are one-based, and we have // an extra frame for the start-state). int32 num_frames = active_toks_.size() - 1; KALDI_ASSERT(num_frames > 0); //生成token到id的映射, 每一帧上都有active token list,顺序访问编号 unordered_map<Token*, StateId> tok_map(num_toks_/2 + 3); // bucket count // First create all states. for (int32 f = 0; f <= num_frames; f++) { if (active_toks_[f].toks == NULL) { KALDI_WARN << "GetRawLattice: no tokens active on frame " << f << ": not producing lattice.\n"; return false; } for (Token *tok = active_toks_[f].toks; tok != NULL; tok = tok->next) tok_map[tok] = ofst->AddState(); } // Now create all arcs,按照token之间跳转关系加上弧Arc,有没有超级简单啊,fst就是好 StateId cur_state = 0; // we rely on the fact that we numbered these // consecutively (AddState() returns the numbers in order..) for (int32 f = 0; f <= num_frames; f++) { for (Token *tok = active_toks_[f].toks; tok != NULL; tok = tok->next, cur_state++) { for (ForwardLink *l = tok->links; l != NULL; l = l->next) { unordered_map<Token*, StateId>::const_iterator iter = tok_map.find(l->next_tok); StateId nextstate = iter->second; KALDI_ASSERT(iter != tok_map.end()); BaseFloat cost_offset = 0.0; if (l->ilabel != 0) { // emitting.. KALDI_ASSERT(f >= 0 && f < cost_offsets_.size()); cost_offset = cost_offsets_[f]; } Arc arc(l->ilabel, l->olabel, Weight(l->graph_cost, l->acoustic_cost - cost_offset), nextstate); ofst->AddArc(cur_state, arc); } if (f == num_frames) { std::map<Token*, BaseFloat>::const_iterator iter = final_costs_.find(tok); if (iter != final_costs_.end()) ofst->SetFinal(cur_state, LatticeWeight(iter->second, 0)); } } } KALDI_ASSERT(cur_state == ofst->NumStates()); return (cur_state != 0); } //先计算raw lattice,然后生成最短路径的lattice bool LatticeFasterDecoder::GetBestPath(fst::MutableFst<LatticeArc> *ofst) const { fst::VectorFst<LatticeArc> fst; if (!GetRawLattice(&fst)) return false; // std::cout << "Raw lattice is:\n"; // fst::FstPrinter<LatticeArc> fstprinter(fst, NULL, NULL, NULL, false, true); // fstprinter.Print(&std::cout, "standard output"); ShortestPath(fst, ofst); return true; } //由最短路径得到的fst,其ilabel就是alignment, 其olabel就是words bool GetLinearSymbolSequence(const Fst<Arc> &fst, vector<I> *isymbols_out, vector<I> *osymbols_out, typename Arc::Weight *tot_weight_out) { typedef typename Arc::Label Label; typedef typename Arc::StateId StateId; typedef typename Arc::Weight Weight; Weight tot_weight = Weight::One(); vector<I> ilabel_seq; vector<I> olabel_seq; StateId cur_state = fst.Start(); if (cur_state == kNoStateId) { // empty sequence. if (isymbols_out != NULL) isymbols_out->clear(); if (osymbols_out != NULL) osymbols_out->clear(); if (tot_weight_out != NULL) *tot_weight_out = Weight::Zero(); return true; } while (1) { Weight w = fst.Final(cur_state); if (w != Weight::Zero()) { // is final.. tot_weight = Times(w, tot_weight); if (fst.NumArcs(cur_state) != 0) return false; if (isymbols_out != NULL) *isymbols_out = ilabel_seq; if (osymbols_out != NULL) *osymbols_out = olabel_seq; if (tot_weight_out != NULL) *tot_weight_out = tot_weight; return true; } else { if (fst.NumArcs(cur_state) != 1) return false; //什么意思,因为这是最短路径的lattice ArcIterator<Fst<Arc> > iter(fst, cur_state); // get the only arc. const Arc &arc = iter.Value(); tot_weight = Times(arc.weight, tot_weight); if (arc.ilabel != 0) ilabel_seq.push_back(arc.ilabel); if (arc.olabel != 0) olabel_seq.push_back(arc.olabel); cur_state = arc.nextstate; } } }
- 同htk的两轮传播,词内传播和词间传播
- Token中ref_count_, 引用计数,类似htk中collected path, new path, old path
- garbage collected
- ProcessNonemitting: 空弧跳转, 队列实现,htk中递归实现
- ProcessEmitting:
- 在解码处理上算法简单化,数据结构更加抽象
- 代码看起来很清晰哈
5.2 三音素决策树
- An event is just a set of (key,value) pairs, with no key repeated
5.2.1 数据结构
- EventMap
- EventKeyType: int
- EventValueType: int
- EventAnswerType: int
- typedef std::vector<std::pair<EventKeyType,EventValueType> > EventType;
- ConstantEventMap: 叶子节点
answer_: 节点id,mono-tree中就是hmm-state的编号
- TableEventMap:
EventKeyType key_: key, -1时子树为叶节点, P时为hmm_sets std::vector<EventMap*> table_: 各个子树 Lookup: 二分查找,event中查找key,返回id MultiMap: 空查找所有,否则查找ans MaxResult: 共多少个节点,返回最大节点编号
- ContextDependency
- gmm-init-mono中如何构建一颗树
- GetPdfInfo: 返回每个pdf对应的音素状态
- to_pdf_
- TransitionModel
- state2id_
- id2state_
- triples_
- ComputeTriples: 计算triples_
- ConputeDerived: 计算state2id_, id2state_
- InitializeProbs: 计算trans_id的log prob
- exp/mono/tree 格式: CE TE SE
5.2.2 Clusterable
class GaussClusterable: public Clusterable { public: virtual void Add(const Clusterable &other_in); virtual void Sub(const Clusterable &other_in); virtual BaseFloat Normalizer() const { return count_; } virtual Clusterable *Copy() const; double count_; Matrix<double> stats_; // two rows: sum, then sum-squared. double var_floor_; // should be common for all objects created.
5.2.3 计算似然和似然增益
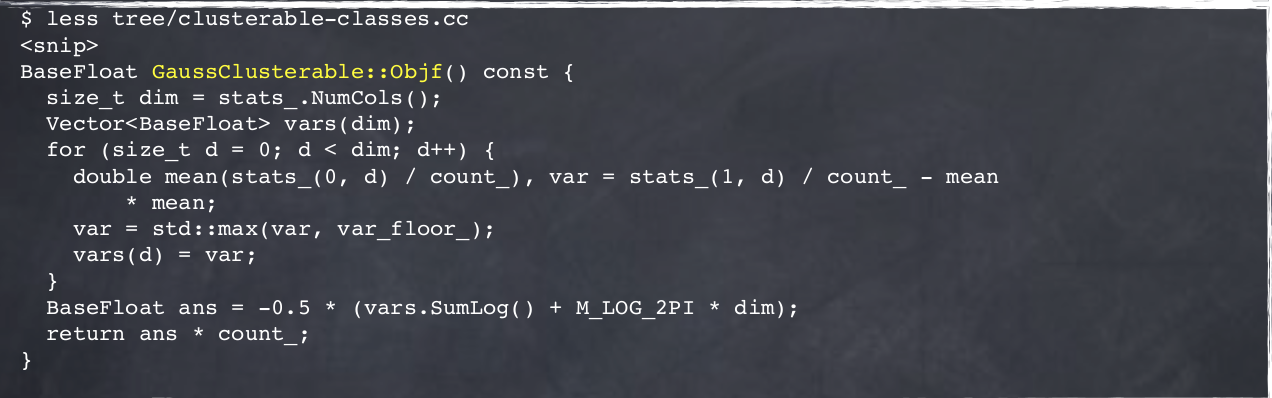


5.2.4 tools & core code
- acc-tree-stats
for (int i = -N; i < static_cast<int>(split_alignment.size()); i++) { // consider window starting at i, only if i+P is within // list of phones. if (i + P >= 0 && i + P < static_cast<int>(split_alignment.size())) { int32 central_phone = MapPhone(phone_map, trans_model.TransitionIdToPhone(split_alignment[i+P][0])); bool is_ctx_dep = ! std::binary_search(ci_phones.begin(), ci_phones.end(), central_phone); EventType evec; for (int j = 0; j < N; j++) { int phone; if (i + j >= 0 && i + j < static_cast<int>(split_alignment.size())) phone = MapPhone(phone_map, trans_model.TransitionIdToPhone(split_alignment[i+j][0])); else phone = 0; // ContextDependency class uses 0 to mean "out of window"; // we also set the phone arbitrarily to 0 // Don't add stuff to the event that we don't "allow" to be asked, due // to the central phone being context-independent: check "is_ctx_dep". // Why not just set the value to zero in this // case? It's for safety. By omitting the key from the event, we // ensure that there is no way a question can ever be asked that might // give an inconsistent answer in tree-training versus graph-building. // [setting it to zero would have the same effect given the "normal" // recipe but might be less robust to changes in tree-building recipe]. if (is_ctx_dep || j == P) evec.push_back(std::make_pair(static_cast<EventKeyType>(j), static_cast<EventValueType>(phone))); } for (int j = 0; j < static_cast<int>(split_alignment[i+P].size());j++) { // for central phone of this window... EventType evec_more(evec); int32 pdf_class = trans_model.TransitionIdToPdfClass(split_alignment[i+P][j]); // pdf_class will normally by 0, 1 or 2 for 3-state HMM. std::pair<EventKeyType, EventValueType> pr(kPdfClass, pdf_class); evec_more.push_back(pr); std::sort(evec_more.begin(), evec_more.end()); // these must be sorted! if (stats->count(evec_more) == 0) (*stats)[evec_more] = new GaussClusterable(dim, var_floor); BaseFloat weight = 1.0; (*stats)[evec_more]->AddStats(features.Row(cur_pos), weight); cur_pos++; } } }
- cluster-phones
// split by phone,根据中间音素分类,并统计 SplitStatsByKey(retained_stats, P, &split_stats); std::vector<Clusterable*> summed_stats; // summed up by phone. SumStatsVec(split_stats, &summed_stats); // 树聚类 std::vector<int32> assignments; // assignment of phones to clusters. dim == summed_stats.size(). std::vector<int32> clust_assignments; // Parent of each cluster. Dim == #clusters. int32 num_leaves; // number of leaf-level clusters. TreeCluster(summed_stats_per_set, summed_stats_per_set.size(), // max-#clust is all of the points. NULL, // don't need the clusters out. &assignments, &clust_assignments, &num_leaves, topts); //调用 TreeClusterer tc(points, max_clust, cfg); BaseFloat ans = tc.Cluster(clusters_out, assignments_out, clust_assignments_out, num_leaves_out); //类TreeCluster class TreeClusterer { //树聚类 BaseFloat Cluster(std::vector<Clusterable*> *clusters_out, std::vector<int32> *assignments_out, std::vector<int32> *clust_assignments_out, int32 *num_leaves_out) { while (static_cast<int32>(leaf_nodes_.size()) < max_clust_ && !queue_.empty()) { std::pair<BaseFloat, Node*> pr = queue_.top(); queue_.pop(); ans_ += pr.first; DoSplit(pr.second); } CreateOutput(clusters_out, assignments_out, clust_assignments_out, num_leaves_out); return ans_; } //对一个节点进行分割 void DoSplit(Node *node) {} //将一个节点进行kmeans聚类, 此处kmeans聚类比较特殊,为保证结果较优,进行了多次不同初始化,并选择效果好的。 void FindBestSplit(Node *node) { // takes a leaf node that has just been set up, and does ClusterKMeans with k = cfg_branch_factor. KALDI_ASSERT(node->is_leaf); if (node->leaf.points.size() == 0) { KALDI_WARN << "Warning: tree clustering: leaf with no data\n"; node->leaf.best_split = 0; return; } if (node->leaf.points.size()<=1) { node->leaf.best_split = 0; return; } else { // use kmeans. BaseFloat impr = ClusterKMeans(node->leaf.points, cfg_.branch_factor, &node->leaf.clusters, &node->leaf.assignments, cfg_.kmeans_cfg); node->leaf.best_split = impr; if (impr > cfg_.thresh) queue_.push(std::make_pair(impr, node)); } } }
- compile-questions
Questions qo; QuestionsForKey phone_opts(num_iters_refine); // the questions-options corresponding to keys 0, 1, .. N-1 which // represent the phonetic context positions (including the central phone). phone_opts.initial_questions = questions; //对每个位置建立问题集 for (int32 n = 0; n < N; n++) { KALDI_LOG << "Setting questions for phonetic-context position "<< n; qo.SetQuestionsOf(n, phone_opts); } QuestionsForKey pdfclass_opts(num_iters_refine); std::vector<std::vector<int32> > pdfclass_questions(max_num_pdfclasses-1); //对kPdfClass=-1问题集[ [0], [0, 1] ] for (int32 i = 0; i < max_num_pdfclasses - 1; i++) for (int32 j = 0; j <= i; j++) pdfclass_questions[i].push_back(j); // E.g. if max_num_pdfclasses == 3, pdfclass_questions is now [ [0], [0, 1] ]. pdfclass_opts.initial_questions = pdfclass_questions; KALDI_LOG << "Setting questions for hmm-position [hmm-position ranges from 0 to "<< (max_num_pdfclasses-1) <<"]"; qo.SetQuestionsOf(kPdfClass, pdfclass_opts);
- build-tree
EventMap *SplitDecisionTree(const EventMap &input_map, const BuildTreeStatsType &stats, Questions &q_opts, BaseFloat thresh, int32 max_leaves, // max_leaves<=0 -> no maximum. int32 *num_leaves, BaseFloat *obj_impr_out, BaseFloat *smallest_split_change_out) { { // Do the splitting. int32 count = 0; std::priority_queue<std::pair<BaseFloat, size_t> > queue; // use size_t because logically these // are just indexes into the array, not leaf-ids (after splitting they are no longer leaf id's). // Initialize queue. for (size_t i = 0; i < builders.size(); i++) queue.push(std::make_pair(builders[i]->BestSplit(), i)); // Note-- queue's size never changes from now. All the alternatives leaves to split are // inside the "DecisionTreeSplitter*" objects, in a tree structure. //此处为重点,优先队列的使用,及决策树终止的两个条件 while (queue.top().first > thresh && (max_leaves<=0 || *num_leaves < max_leaves)) { smallest_split_change = std::min(smallest_split_change, queue.top().first); size_t i = queue.top().second; like_impr += queue.top().first; builders[i]->DoSplit(num_leaves); queue.pop(); queue.push(std::make_pair(builders[i]->BestSplit(), i)); count++; } KALDI_LOG << "DoDecisionTreeSplit: split "<< count << " times, #leaves now " << (*num_leaves); } ... } 寻找最优问题集类 class DecisionTreeSplitter { //返回最优的一个分割增益 BaseFloat BestSplit() { return best_split_impr_; } // returns objf improvement (>=0) of best possible split. //构造函数中即从问题集中寻找最优问题 DecisionTreeSplitter(EventAnswerType leaf, const BuildTreeStatsType &stats, const Questions &q_opts): q_opts_(q_opts), yes_(NULL), no_(NULL), leaf_(leaf), stats_(stats) { // not, this must work when stats is empty too. [just gives zero improvement, non-splittable]. FindBestSplit(); } //在all_keys中找最优 void FindBestSplit() {} }; BaseFloat ComputeInitialSplit(const std::vector<Clusterable*> &summed_stats, const Questions &q_opts, EventKeyType key, std::vector<EventValueType> *yes_set) { ... const std::vector<std::vector<EventValueType> > &questions_of_this_key = key_opts.initial_questions; int32 best_idx = -1; BaseFloat best_objf_change = 0; //在问题集中寻找似然增益最大的问题 for (size_t i = 0; i < questions_of_this_key.size(); i++) { const std::vector<EventValueType> &yes_set = questions_of_this_key[i]; std::vector<int32> assignments(summed_stats.size(), 0); // 0 is index of "no". std::vector<Clusterable*> clusters(2); // no and yes clusters. for (std::vector<EventValueType>::const_iterator iter = yes_set.begin(); iter != yes_set.end(); iter++) { KALDI_ASSERT(*iter>=0); if (*iter < (EventValueType)assignments.size()) assignments[*iter] = 1; } kaldi::AddToClustersOptimized(summed_stats, assignments, *total, &clusters); BaseFloat this_objf = SumClusterableObjf(clusters); if (this_objf < unsplit_objf- 0.001*std::abs(unsplit_objf)) { // got worse; should never happen. // of course small differences can be caused by roundoff. KALDI_WARN << "Objective function got worse when building tree: "<< this_objf << " < " << unsplit_objf; KALDI_ASSERT(!(this_objf < unsplit_objf - 0.01*(200 + std::abs(unsplit_objf)))); // do assert on more stringent check. } BaseFloat this_objf_change = this_objf - unsplit_objf; if (this_objf_change > best_objf_change) { best_objf_change = this_objf_change; best_idx = i; } DeletePointers(&clusters); } delete total; if (best_idx != -1) *yes_set = questions_of_this_key[best_idx]; return best_objf_change; }
5.3 DNN
5.3.1 component
神经网络由多层的Component拼接而成,即Component为其基本组件。Component中引申出UpdatableComponent,即含有连接权值的Component,如:
- Component: Sigmoid, Softmax, Tanh, max-pooling等
- UpdatableComponent: AffineTransform, LinearTransform, ConvolutionalComponent等。
- loss: Mse, Xent(交叉熵)
//Componet子类需实现PropagateFnc和BackpropagateFnc接口 class Sigmoid : public Component { public: void PropagateFnc(const CuMatrixBase<BaseFloat> &in, CuMatrixBase<BaseFloat> *out) { // y = 1/(1+e^-x) out->Sigmoid(in); } void BackpropagateFnc(const CuMatrixBase<BaseFloat> &in, const CuMatrixBase<BaseFloat> &out, const CuMatrixBase<BaseFloat> &out_diff, CuMatrixBase<BaseFloat> *in_diff) { // ey = y(1-y)ex in_diff->DiffSigmoid(out, out_diff); } }; //UpdatableComponent还需实现Update()接口 class UpdatableComponent : public Component { public: //updatable bool IsUpdatable() const { return true; } /// Compute gradient and update parameters virtual void Update(const CuMatrixBase<BaseFloat> &input, const CuMatrixBase<BaseFloat> &diff) = 0; protected: /// Option-class with training hyper-parameters NnetTrainOptions opts_; }; //UpdatableComponent参数初始化 void InitData(std::istream &is)
5.3.2 nnet
一个神经网络的封装,将components及其前向后向拼接起来。
private: std::vector<Component*> components_; std::vector<CuMatrix<BaseFloat> > propagate_buf_; ///< buffers for forward pass std::vector<CuMatrix<BaseFloat> > backpropagate_buf_; ///< buffers for backward pass void Nnet::Propagate(const CuMatrixBase<BaseFloat> &in, CuMatrix<BaseFloat> *out) { propagate_buf_[0].Resize(in.NumRows(), in.NumCols()); propagate_buf_[0].CopyFromMat(in); for(int32 i=0; i<(int32)components_.size(); i++) { components_[i]->Propagate(propagate_buf_[i], &propagate_buf_[i+1]); } (*out) = propagate_buf_[components_.size()]; } void Nnet::Backpropagate(const CuMatrixBase<BaseFloat> &out_diff, CuMatrix<BaseFloat> *in_diff) { // copy out_diff to last buffer backpropagate_buf_[NumComponents()] = out_diff; // backpropagate using buffers for (int32 i = NumComponents()-1; i >= 0; i--) { components_[i]->Backpropagate(propagate_buf_[i], propagate_buf_[i+1], backpropagate_buf_[i+1], &backpropagate_buf_[i]); if (components_[i]->IsUpdatable()) { UpdatableComponent *uc = dynamic_cast<UpdatableComponent*>(components_[i]); uc->Update(propagate_buf_[i], backpropagate_buf_[i+1]); } } // eventually export the derivative if (NULL != in_diff) (*in_diff) = backpropagate_buf_[0]; }
5.3.3 nnet-train-frmshuff
Perform one iteration of Neural Network training by mini-batch Stochastic Gradient Descent
- 先对特征打乱,并按组分为minibatch大小
- 利用suffle的数据训练DNN
--cross-validate: Perform cross-validation (don't backpropagate) --objective-function: xent or mes –feature-transform, this can be a Nnet which does on-the-fly feature transformation --minibatch-size
//minibatch在这里面 NnetDataRandomizerOptions rnd_opts; rnd_opts.Register(&po);
5.4 CNN
5.4.1 keypoint
- convolution only frequence axis, 卷积窗仅在频域轴上移动
- feature type, 将时域拼接的上下文帧转换为frequency bands特征
- convolution over all axis, 即不使用local filter,在整个频域上使用相同核
- fast implementation, 将二维滤波器(卷积核)拉伸为一维向量
5.4.2 代码解析
因为卷积核移动和不同的卷积核,输入与输出之间是一对多的关系,一般是按输入顺序查找输出。这里的一个技巧是先确定出输出的维度,查找与之相应的输入,前向,后向,卷积和pooling时均使用该技巧。
- 卷积层 nnet-convolution-component.h
void PropagateFnc(const CuMatrixBase<BaseFloat> &in, CuMatrixBase<BaseFloat> *out) { // useful dims int32 num_splice = input_dim_ / patch_stride_; //帧数 int32 num_patches = 1 + (patch_stride_ - patch_dim_) / patch_step_; //patch num int32 num_filters = filters_.NumRows(); //filter数量,一行为一个filter int32 num_frames = in.NumRows(); //batch中的数据数 int32 filter_dim = filters_.NumCols(); //filter的核大小 // we will need the buffers if (vectorized_feature_patches_.size() == 0) { vectorized_feature_patches_.resize(num_patches); feature_patch_diffs_.resize(num_patches); } /* Prepare feature patches, the layout is: * |----------|----------|----------|---------| (in = spliced frames) * xxx xxx xxx xxx (x = selected elements) * * xxx : patch dim * xxx * ^---: patch step * |----------| : patch stride * * xxx-xxx-xxx-xxx : filter dim * */ for (int32 p=0; p<num_patches; p++) { vectorized_feature_patches_[p].Resize(num_frames, filter_dim, kSetZero); // build-up a column selection mask: std::vector<int32> column_mask; /* *|-XXX---------| *|-XXX---------| *|-XXX---------| *|-XXX---------| column_mask的位置, p * patch_step + s * patch_stride_ + d */ for (int32 s=0; s<num_splice; s++) { for (int32 d=0; d<patch_dim_; d++) { column_mask.push_back(p * patch_step_ + s * patch_stride_ + d); } } KALDI_ASSERT(column_mask.size() == filter_dim); // select the current patch columns, 一行为一个输入数据。 vectorized_feature_patches_[p].CopyCols(in, column_mask); } // compute filter activations for (int32 p=0; p<num_patches; p++) { //patch p 在输出中的位置tgt CuSubMatrix<BaseFloat> tgt(out->ColRange(p * num_filters, num_filters)); tgt.AddVecToRows(1.0, bias_, 0.0); // add bias // apply all filters tgt.AddMatMat(1.0, vectorized_feature_patches_[p], kNoTrans, filters_, kTrans, 1.0); } } //后向程序仅是对公式的翻译 void BackpropagateFnc(const CuMatrixBase<BaseFloat> &in, const CuMatrixBase<BaseFloat> &out, const CuMatrixBase<BaseFloat> &out_diff, CuMatrixBase<BaseFloat> *in_diff) { } void Update(const CuMatrixBase<BaseFloat> &input, const CuMatrixBase<BaseFloat> &diff) { }
- pooling层 nnet-max-pooling-component.h
void PropagateFnc(const CuMatrixBase<BaseFloat> &in, CuMatrixBase<BaseFloat> *out) { // useful dims int32 num_patches = input_dim_ / pool_stride_; int32 num_pools = 1 + (num_patches - pool_size_) / pool_step_; //pool_step_ pool步移, pool_size_,pool步长 // do the max-pooling (pools indexed by q),为每个输出q选择max for (int32 q = 0; q < num_pools; q++) { // get output buffer of the pool CuSubMatrix<BaseFloat> pool(out->ColRange(q*pool_stride_, pool_stride_)); pool.Set(-1e20); // reset (large negative value) for (int32 r = 0; r < pool_size_; r++) { // max int32 p = r + q * pool_step_; // p = input patch pool.Max(in.ColRange(p*pool_stride_, pool_stride_)); //*this = max(*this, A) } } } //max-pool,若其为max,后向误差乘以1,否则0,这里有个scale的操作 //因为中间部分可能多次计算,相对的边缘部分在shift中计算次数较少 void BackpropagateFnc(const CuMatrixBase<BaseFloat> &in, const CuMatrixBase<BaseFloat> &out, const CuMatrixBase<BaseFloat> &out_diff, CuMatrixBase<BaseFloat> *in_diff) { // useful dims int32 num_patches = input_dim_ / pool_stride_; int32 num_pools = 1 + (num_patches - pool_size_) / pool_step_; //scale 数组 std::vector<int32> patch_summands(num_patches, 0); in_diff->SetZero(); // reset //遍历所有pool输出 for(int32 q=0; q<num_pools; q++) { // sum for(int32 r=0; r<pool_size_; r++) { //对应q时的输入 int32 p = r + q * pool_step_; // patch number CuSubMatrix<BaseFloat> in_p(in.ColRange(p*pool_stride_, pool_stride_)); CuSubMatrix<BaseFloat> out_q(out.ColRange(q*pool_stride_, pool_stride_)); CuSubMatrix<BaseFloat> tgt(in_diff->ColRange(p*pool_stride_, pool_stride_)); CuMatrix<BaseFloat> src(out_diff.ColRange(q*pool_stride_, pool_stride_)); //find max mask CuMatrix<BaseFloat> mask; in_p.EqualElementMask(out_q, &mask); src.MulElements(mask); tgt.AddMat(1.0, src); patch_summands[p] += 1; } } //scale操作 for(int32 p=0; p<num_patches; p++) { CuSubMatrix<BaseFloat> tgt(in_diff->ColRange(p*pool_stride_, pool_stride_)); KALDI_ASSERT(patch_summands[p] > 0); // patch at least in one pool tgt.Scale(1.0/patch_summands[p]); } }
5.5 一些工具解析
5.5.1 ali-to-post: make_pair<alignment, 1.0>, Convert alignments to viterbi style posteriors
void AlignmentToPosterior(const std::vector<int32> &ali, Posterior *post) { post->clear(); post->resize(ali.size()); for (size_t i = 0; i < ali.size(); i++) { (*post)[i].resize(1); (*post)[i][0].first = ali[i]; (*post)[i][0].second = 1.0; } }
5.5.2 kaldi log(base/kaldi-error.h)
class KaldiLogMessage { public: inline std::ostream &stream() { return ss; } KaldiLogMessage(const char *func, const char *file, int32 line); ~KaldiLogMessage() { fprintf(stderr, "%s\n", ss.str().c_str()); } private: std::ostringstream ss; }; #define KALDI_LOG kaldi::KaldiLogMessage(__func__, __FILE__, __LINE__).stream() KaldiLogMessage::KaldiLogMessage(const char *func, const char *file, int32 line) { this->stream() << "LOG (" << GetProgramName() << func << "():" << GetShortFileName(file) << ':' << line << ") "; }
5.5.3 kaldi中的并行run.pl
- 主要特点
- 错误日志
- 计算时间
- 在log文件首行打印所执行命令的实际参数信息
- 因此在不并行的时候也能看到使用$cmd
- 示例
$cmd JOB=1:$nj $dir/log/acc_tree.JOB.log \ acc-tree-stats --ci-phones=$ciphonelist $alidir/final.mdl "$feats" \ "ark:gunzip -c $alidir/ali.JOB.gz|" $dir/JOB.treeacc || exit 1; #等价于如下shell for ((i=1; i<=$JOB; i++)); do { #my operate }& #并行 done wait #等待所有子进程结束
- run.pl源码
#JOB if ($ARGV[0] =~ m/^([\w_][\w\d_]*)+=(\d+):(\d+)$/) { # e.g. JOB=1:10 $jobname = $1; $jobstart = $2; $jobend = $3; } #创建子进程 for ($jobid = $jobstart; $jobid <= $jobend; $jobid++) { $childpid = fork(); } #等待子进程结束 for ($jobid = $jobstart; $jobid <= $jobend; $jobid++) { $r = wait(); if ($r == -1) { die "Error waiting for child process"; } # should never happen. if ($? != 0) { $numfail++; $ret = 1; } # The child process failed. }
6 Kaldi Keypoint
- TODO SGMM
- TODO MAP, Mlle
- TODO occ
- 降维,且降维后使S_b 类间距要大,类内距离S_w 要小,等价于求WS_b W/WS_w W, 经推导最终
- 经典HMM状态内帧间独立性的假设使得帧间相关的信息在HMM模型中没有得到很好的利用,而帧间
6.1 GMM
6.1.1 TODO 如何加高斯,gmm split & merge
6.1.2 训练时每个模型的高斯数不一定相等,有意思哈!
6.1.3 AmGMM.Split()
$$id=arg max w_{k}$$ $$w_{n}=w_{max}/2$$ $$\mu_{n}=\mu_{id}$$ $$\Sigma_{n}= \Sigma_{id}$$ \(w_{n}\) 为新加入高斯权值,\(\mu\) 均值, \(\Sigma\) 方差
大侠的解释:从EM的角度考虑如何给GMM加高斯,为了增加模型的精度,所以需分割权值最大的Gauss,根据上面的公式计算, 但是这样EM迭代时,新加入Gauss会与原Gauss一样,所以还需加入扰动。
6.2 训练方式
6.2.1 lda(Linear Discriminant Analysis)
等价于求S_w 的逆乘S_b 的特征值和特征向量。
线性判别分析相关信息对识别率的提高有很重要的作用。
6.2.2 mllt(Maximum Likelihood Linear Transformation)
目前的语音识别系统大多都采用隐马尔可夫模型(Hidden Markov Model, HMM),但在实际应用中为了减少存 储空间和降低计算量,通常会假设输入HMM的协方差矩阵仅为对角线上有值(其他元素均为 0)。这样,通过PCA和LDA 得到的协方差矩阵不符合应用 HMM 的假设,造成失真从而影响识别率。本文引进最大似然线性转换(Maximum Likelihood Linear Transformation, MLLT)改进PCA和LDA。与PCA和LDA相似,MLLT也是通过求取一个变换矩阵来 变换矢量空间, MLLT不会对数据进行降维,但可使变换后模式样本的协方差矩阵对角化。这样,通过MLLT后得到的 协方差矩阵就可以满足应用 HMM 的假设了。
6.2.3 sat
自适应
6.2.4 sgmm(subspace gmm)
这个是什么原理,不懂哈
6.2.5 mmi
Maximum Mutual Information(MMI)
Minimum Phone Error(MPE) Minimum Word Error(MWE)
7 Kaldi二进制文件查看
- gmm-copy –binary=false exp/mono/0.mdl - | less
- copy-tree –binary=false exp/mono/tree - | less
- show-alignments data/lang/phones.txt exp/mono/0.mdl ark:exp/mono/cur.ali | less
- show-transitions data/lang/phones.txt exp/mono/0.mdl
- sum-tree-stats –binary=false - exp/tri1/treeacc | less
- utils/int2sym.pl data/lang/phones.txt < exp/tri1/questions.int
- ali-to-phones exp_decode/mono_ali/final.mdl "ark:gunzip -c exp_decode/mono_ali/ali.1.gz|" ark,t:- | less
8 fst
Created by:robin1001
8.1 定义
- P(Q1, Q2): Q1到Q2的所有路径
- P(Q1, x, Q2): 接受x的Q1->Q2 | A
- P(Q1, x, y, Q2): 接受x,输出y的Q1->Q2 | T
- [A](x): 接受x的所有路径 | A
- [T](x, y) 接受x,输出y的所有路径 | T
8.2 空转移
- 算法插入
- 一对多的映射(比如…)
8.3 A & T
在Acceptor中使input和output相同即可模拟transducer
8.4 运算
- union: 或运算
- concate: 连接
- closure: 闭包
- reverse: 反转
- inverse: 逆,input和output对调
- project: T->A
- composition: 组合,将不同层次的信息组合起来
- 含epsilon和不含epsilon两种模型
- 组合算法
8.5 确定化
8.5.1 何为确定化
- 单一初始状态
- 一个状态不存在input相同的两条出弧
- openfst和ATT FSM将epsilon作为一个正常的symbol
8.5.2 确定化算法
- 算法简单理解:合并公共前缀
8.6 最小化
- 算法简单理解:合并公共后缀
8.7 Weight Pushing
- 权重可以向init states | final states移动
- 应用:arc权重的归一化
8.8 Epsilon消除
8.9 linux fst 程序编译
g++ -O0 fst.cpp -o fst -I/home/robin1001/kaldi/kaldi-trunk/tools/openfst/include -L/home/robin1001/kaldi/kaldi-trunk/tools/openfst/lib -lfst -Wl,-rpath,/home/robin1001/kaldi/kaldi-trunk/tools/openfst/lib -Wl,rpath=<your_lib_dir>,使得execute记住链接库的位置
8.10 数据结构
8.10.1 StdArc
struct StdArc { typedef int Label; typedef TropicalWeight Weight; // see "FST Weights" below typedef int StateId; Label ilabel; Label olabel; Weight weight; StateId nextstate; }; for (ArcIterator<StdFst> aiter(fst, i); !aiter.Done(); aiter.Next()) const StdArc &arc = aiter.Value(); Matcher<StdFst> matcher(fst, MATCH_INPUT); matcher.SetState(i); if (matcher.Find(l)) for (; !matcher.Done(); matcher.Next()) const StdArc &arc = matcher.Value();
8.10.2 fst
//抽象类 Fst<Arc> ExpandedFst<Arc>: +NumStates(); MutableFst<Arc>: 可变的fst,如AddStates(), SetStart() //实现 VectorFst<Arc>: mutable fst ConstFst<Arc>: immutable fst ComposeFst<Arc> //StdArc ilabel, olabel, weight(Weight), nextstate //Weight TropicalWeight, LogWeight, ProductWeight //Fst Start(), Final(), Read(), etc ... //Mutable Fst SetStart(), SetFinal(), AddState(), AddArc() //StateIterator Done(), Value(), Next(), Reset() //ArcIterator Done(), Value(), Next(), Reset() //FstImple: public Fst type_, isymbols_, osymbols_, ref_count_ //SymbolTable Impl: 包装SymbolTable map<int64, const char*> key_map_; vector<const char *> symbols_; //VectorState final, Vector<A> arcs, niepsilon, noepsilon //VectorFstBaseImpl: 这个类是VectorFst的一系列实现 state_; vector<State *>states; StateId AddState() { states.push_back(new State()) etc ...
8.11 半环
8.11.1 幺半群
三元组<A, *, 1>, 其中:
- 1为恒等元素,1*a=a*1
- a*b=b*a
8.11.2 半环
五元组 <A, +, *, 0, 1>, 其中
- <A, +, 0> 为交换幺半群
- <A, *, 1> 为幺半群
- a*(b+c) = a*b+a*c
- 0*a = a*0 = 0
8.11.3 Moore & Mealy
- Morre机:每个状态产生输出
- Mealy机:每个移动产生输出
8.12 openfst
fstcompile –isymbols=isyms.txt –osymbols=osyms.txt text.fst binary.fst fstdraw –isymbols=isyms.txt –osymbols=osyms.txt binary.fst binary.dot dot -Tps binary.dot >binary.ps
9 Google C++ Style Guide
- 函数超过10行时不要使用內联
- -inl.h內联函数实现文件 | 定义函数模板
- 输入:const型,输出参数:指针
- 最好给纯接口类加上Interface后缀
- 名称为foo_的变量其访问函数为foo(),而其修改器(mutator)则为set_foo(),访问器常在头文件中定义为内联函数。
- 请按下面的规则次序来定义类:公共成员位于私有成员前;方法位于数据成员前(变量)等等。
- scoped_ptr | shared_ptr
- 使用cpplint.py来检测风格错误
- 类型转换(Casting),需要类型转换时请使用static_cast<>()
- 类成员以下划线结束 int val_;
- 禁止使用异常
- 常量命名, 在名称前加k:kDaysInAWeek
const int kDaysInAWeek = 7;
- 函数形式参数位置和花括号位置
ReturnType ClassName::ReallyLongFunctionName(Type par_name1) { }