参考文献
- Notes on Convolutional Neural Networks
- Applying Convolutional Neural Networks Concepts to Hybrid NN-HMM Model for Speech Recognition
- IBM-Tara N. Sainath-Deep Convolutional Neural Networks for LVCSR
- code guide: DeeplearnToolbox & kaldi CNN
卷积特征提取
离散卷积
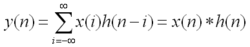
- 卷积的长度M+N-1,不补0有效长度M-N+1
- 重要性质之一:交换律
%matlab 卷积函数
conv(x, h, 'full') %所有长度,M+N-1
conv(x, h, 'valid') %有效长度,M-N+1
图片特征提取
- NN在图像中的问题:参数多,图片的局部性
- 卷积提取特征,如均值滤波窗,Gasussion模糊,Laplace算子,梯度算子,SIFT中的LoG


卷积神经网络结构
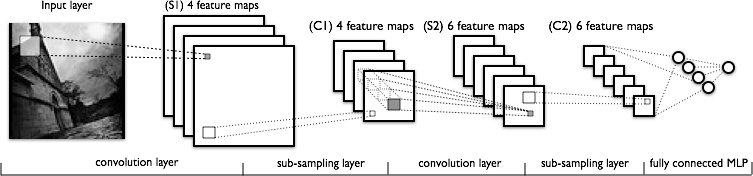
- 卷积层C,所谓的权值共享
- 降采样层S, Pooling
- 全连接层,就是NN
CNN算法
这里主要参考”Notes on Convolutional Neural Networks”中的公式推导,前向和后向算法均以卷积形式给出。 具体的实现也以DeeplearnxToolbox中CNN在mnist库上的应用为例。
前向
- 卷积层:第一层时仅有输入图片一个输入,中间卷积层结果是对输入卷积Kij的累和。
- pooling: average, max, stochastic
max pooling的意思就是用图像某一区域像素值的最大值来表示该区域的特征,而mean pool的意思用图像某一区域像素值的均值来表示该区域的特征。这两个pooling操作都提高了提取特征的不变性,而特征提取的误差主要来自两个方面:(1)邻域大小受限造成的估计值方差增大;(2)卷积层参数误差造成估计均值的偏移。一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。在图像处理中,使用max pooling多于mean pooling
后向ebp
- 降采样层对 $\delta$ 升采样,一一对应
- 若降采样层后为全连接层,计算方式与普通NN相同,所以此处仅考虑降采样层后为卷积层的形式。
在语音识别中的应用
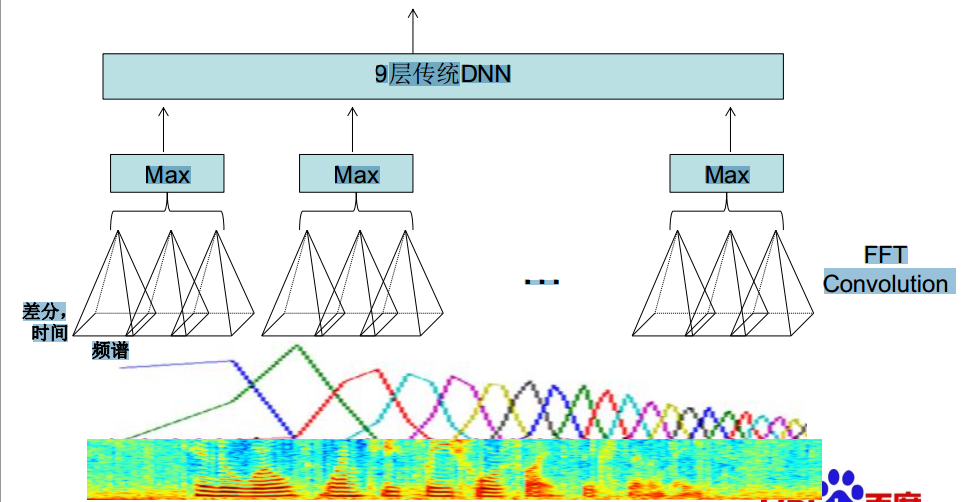
卷积窗仅在频域轴上移动,同一个patch不同滤波器作用的结果分为一组(h1, h2, …, hn),max pooling时在patch_step中的hn中取max,例h1 = (1, 3, 2), h2 = (2, 1, 1), h1 h2为一个patch,max pooling的结果为(2, 3, 2)。
keypoint
- convolution only frequence axis, 卷积窗仅在频域轴上移动
- feature type, filter-bank特征,按频率分组,将时域拼接的上下文帧转换为frequency bands特征
- convolution over all axis, 即不使用local filter,在整个频域上使用相同核
- fast implementation, 将二维滤波器(卷积核)拉伸为一维向量
- 语音识别中卷积(滤波器)的使用
的使用")
语音识别卷积神经网络的深度结构(多个全连接层)
kaldi CNN代码解析
因为卷积核移动和不同的卷积核,输入与输出之间是一对多的关系,一般是按输入顺序查找输出。这里的一个技巧是先确定出输出的维度,查找与之相应的输入,前向,后向,卷积和pooling时均使用该技巧。
卷积层 nnet-convolution-component.h
void PropagateFnc(const CuMatrixBase<BaseFloat> &in, CuMatrixBase<BaseFloat> *out) {
// useful dims
int32 num_splice = input_dim_ / patch_stride_; //帧数
int32 num_patches = 1 + (patch_stride_ - patch_dim_) / patch_step_; //patch num
int32 num_filters = filters_.NumRows(); //filter数量,一行为一个filter
int32 num_frames = in.NumRows(); //batch中的数据数
int32 filter_dim = filters_.NumCols(); //filter的核大小
// we will need the buffers
if (vectorized_feature_patches_.size() == 0) {
vectorized_feature_patches_.resize(num_patches);
feature_patch_diffs_.resize(num_patches);
}
/* Prepare feature patches, the layout is:
* |----------|----------|----------|---------| (in = spliced frames)
* xxx xxx xxx xxx (x = selected elements)
*
* xxx : patch dim
* xxx
* ^---: patch step
* |----------| : patch stride
*
* xxx-xxx-xxx-xxx : filter dim
*
*/
for (int32 p=0; p<num_patches; p++) {
vectorized_feature_patches_[p].Resize(num_frames, filter_dim, kSetZero);
// build-up a column selection mask:
std::vector<int32> column_mask;
/*
*|-XXX---------|
*|-XXX---------|
*|-XXX---------|
*|-XXX---------|
column_mask的位置, p * patch_step + s * patch_stride_ + d
*/
for (int32 s=0; s<num_splice; s++) {
for (int32 d=0; d<patch_dim_; d++) {
column_mask.push_back(p * patch_step_ + s * patch_stride_ + d);
}
}
KALDI_ASSERT(column_mask.size() == filter_dim);
// select the current patch columns, 一行为一个输入数据。
vectorized_feature_patches_[p].CopyCols(in, column_mask);
}
// compute filter activations
for (int32 p=0; p<num_patches; p++) {
//patch p 在输出中的位置tgt
CuSubMatrix<BaseFloat> tgt(out->ColRange(p * num_filters, num_filters));
tgt.AddVecToRows(1.0, bias_, 0.0); // add bias
// apply all filters
tgt.AddMatMat(1.0, vectorized_feature_patches_[p], kNoTrans, filters_, kTrans, 1.0);
}
}
//后向程序仅是对公式的翻译
void BackpropagateFnc(const CuMatrixBase<BaseFloat> &in, const CuMatrixBase<BaseFloat> &out,
const CuMatrixBase<BaseFloat> &out_diff, CuMatrixBase<BaseFloat> *in_diff) {
}
void Update(const CuMatrixBase<BaseFloat> &input, const CuMatrixBase<BaseFloat> &diff) {
}
pooling层 nnet-max-pooling-component.h
void PropagateFnc(const CuMatrixBase<BaseFloat> &in, CuMatrixBase<BaseFloat> *out) {
// useful dims
int32 num_patches = input_dim_ / pool_stride_;
int32 num_pools = 1 + (num_patches - pool_size_) / pool_step_;
//pool_step_ pool步移, pool_size_,pool步长
// do the max-pooling (pools indexed by q),为每个输出q选择max
for (int32 q = 0; q < num_pools; q++) {
// get output buffer of the pool
CuSubMatrix<BaseFloat> pool(out->ColRange(q*pool_stride_, pool_stride_));
pool.Set(-1e20); // reset (large negative value)
for (int32 r = 0; r < pool_size_; r++) { // max
int32 p = r + q * pool_step_; // p = input patch
pool.Max(in.ColRange(p*pool_stride_, pool_stride_)); //*this = max(*this, A)
}
}
}
//max-pool,若其为max,后向误差乘以1,否则0,这里有个scale的操作
//因为中间部分可能多次计算,相对的边缘部分在shift中计算次数较少
void BackpropagateFnc(const CuMatrixBase<BaseFloat> &in, const CuMatrixBase<BaseFloat> &out,
const CuMatrixBase<BaseFloat> &out_diff, CuMatrixBase<BaseFloat> *in_diff) {
// useful dims
int32 num_patches = input_dim_ / pool_stride_;
int32 num_pools = 1 + (num_patches - pool_size_) / pool_step_;
//scale 数组
std::vector<int32> patch_summands(num_patches, 0);
in_diff->SetZero(); // reset
//遍历所有pool输出
for(int32 q=0; q<num_pools; q++) { // sum
for(int32 r=0; r<pool_size_; r++) {
//对应q时的输入
int32 p = r + q * pool_step_; // patch number
CuSubMatrix<BaseFloat> in_p(in.ColRange(p*pool_stride_, pool_stride_));
CuSubMatrix<BaseFloat> out_q(out.ColRange(q*pool_stride_, pool_stride_));
CuSubMatrix<BaseFloat> tgt(in_diff->ColRange(p*pool_stride_, pool_stride_));
CuMatrix<BaseFloat> src(out_diff.ColRange(q*pool_stride_, pool_stride_));
//find max mask
CuMatrix<BaseFloat> mask;
in_p.EqualElementMask(out_q, &mask);
src.MulElements(mask);
tgt.AddMat(1.0, src);
patch_summands[p] += 1;
}
}
//scale操作
for(int32 p=0; p<num_patches; p++) {
CuSubMatrix<BaseFloat> tgt(in_diff->ColRange(p*pool_stride_, pool_stride_));
KALDI_ASSERT(patch_summands[p] > 0); // patch at least in one pool
tgt.Scale(1.0/patch_summands[p]);
}
}