参考文献
- Theano-MPI: a Theano-based Distributed Training Framework
- Deep learning with Elastic Averaging SGD
- SCALABLE TRAINING OF DEEP LEARNING MACHINES BY INCREMENTAL BLOCK TRAINING WITH INTRA-BLOCK PARALLEL OPTIMIZATION AND BLOCKWISE MODEL-UPDATE FILTERING
- https://github.com/Microsoft/CNTK/wiki/Multiple-GPUs-and-machines
- http://chuansong.me/n/316789851542
- Parallel training of DNNs with natural gradient and parameter averaging
思路和方法
并行化和分布式计算一直是大规模机器学习中一个让人兴奋的话题, 特别是今天,越来越多 的数据被应用到深度神经网络的训练中, 对训练速度提出了很高的要求。例如,1000h的语音数据 的复杂模型(LSTM, BLSTM)训练单卡需要一周左右的时间,大部分时间在等模型。 最近,研究了一下近年的关于深度学习的分布式训练的论文和算法,并尝试进行了简单实现。
主流的深度学习的分布式训练大致可以分为两类,基于模型的并行和基于数据的并行。基于模型的 并行,每个worker分到模型的不同部分,仅负责对局部模型参数的更新,类似Hogwild!方法。 数据并行则是在不同worker上使用不同的数据,适于大量数据和较小模型的训练方式。
另外一个分类方法是根据模型更新方法可以分为两类,基于梯度的模型更新和直接基于模型的更新。 基于梯度的模型更新,server的模型更新依赖于梯度计算,如DownpourSGD(既DistBelief)。 直接基于模型的更新,server和worker的模型更新直接基于模型,通过模型之间的计算更新,如 BSP(Model Average), EASGD和BMUF等。
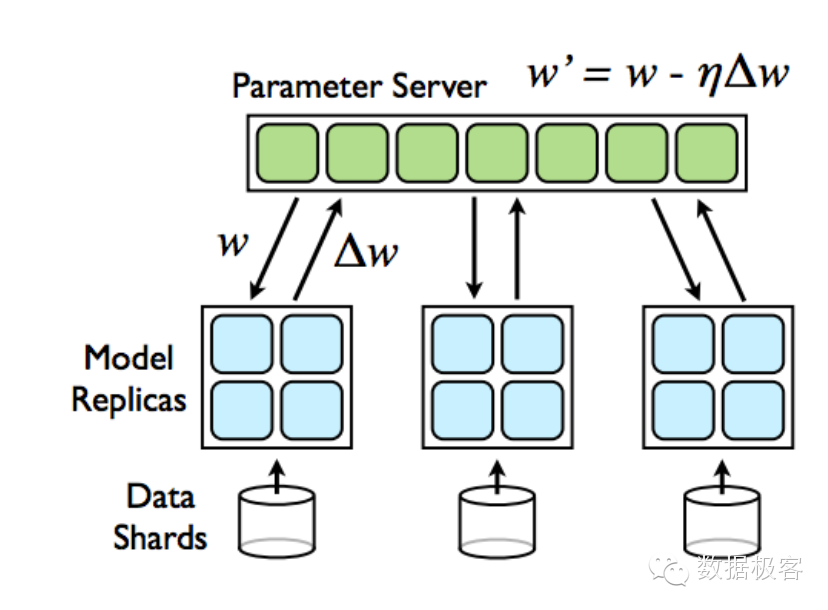
下面是BSP,EASGD和BMUF的基本原理和自己的简单实现。
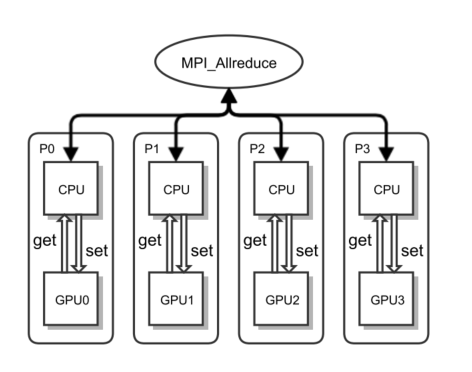
BSP(Bulk Synchronize Parallel, Model Average)
BSP或者模型平均,思路十分简单,每隔一段时间对所有worker上的模型做下平均作为更新后的新模型。 基于MPI的实现也十分简单,直接使用MPI_Allreduce函数即可。 Povey的论文”Parallel training of DNNs with natural gradient and parameter averaging”中对这种方法 进行了讨论,kaldi的nnet2的并行也基于Model Average。
BSP with MPI
Worker Code
bool BspWorker::Synchronize(int num_worker_samples) {
int num_all_samples = num_worker_samples;
AllReduce(&num_all_samples, 1);
// All workers finished it's data, return instantly
if (num_all_samples <= 0) {
KALDI_LOG << "All worker finished their data";
return false;
}
// 1. Calc scale
float factor = float(num_worker_samples) / num_all_samples;
KALDI_ASSERT(factor >= 0.0 && factor <= 1.0);
// 2. Do average
KALDI_ASSERT(gpu_params_.size() == cpu_params_.size());
for (int i = 0; i < gpu_params_.size(); i++) {
// scale factor
gpu_params_[i]->Scale(factor);
// copy from gpu to host
cpu_params_[i]->CopyFromVec(*gpu_params_[i]);
// sum, average
AllReduce(cpu_params_[i]->Data(), cpu_params_[i]->Dim());
// copy to gpu
gpu_params_[i]->CopyFromVec(*cpu_params_[i]);
}
return true;
}
EASGD(Elastic Averaging SGD)
EASGD的优化目标为使所有worker上的loss最小,并且各个worker与server之间的模型差异也要小, 这样把worker节点上的参数跟参数服务器的中心变量联系在一起,这样使得Worker本地的变量会围绕中心变量进行变化。 该算法是Facebook和Yan LeCun团队的成果,需要使用server参数服务器。
EASGD Algorithm

Server Code
void EasgdServer::Run() {
int num_running_workers = NumNodes() - 1;
MPI_Status status;
int msg_type, worker_rank;
while (num_running_workers > 0) {
// tag 0, msg type
MPI_Recv(&msg_type, 1, MPI_INT, MPI_ANY_SOURCE, MPI_ANY_SOURCE,
MPI_COMM_WORLD, &status);
worker_rank = status.MPI_SOURCE;
KALDI_LOG << "Worker rank " << worker_rank << " Msg " << msg_type;
switch (msg_type) {
case kMsgFinished:
num_running_workers--;
KALDI_LOG << "Worker " << worker_rank << " Finished ";
break;
case kMsgSynchronize:
Update(worker_rank);
break;
default:
KALDI_WARN << "Unknown mpi msg type " << msg_type;
}
}
KALDI_LOG << "All worker finished";
}
void EasgdServer::Update(int worker_rank) {
// 1. copy server_gpu_params_ to server_cpu_params_
for (int i = 0; i < server_cpu_params_.size(); i++) {
server_cpu_params_[i]->CopyFromVec(*server_gpu_params_[i]);
}
// 2. send server_cpu_params_ and recv worker_cpu_params_
MPI_Status status;
for (int i = 0; i < server_cpu_params_.size(); i++) {
MPI_Sendrecv(server_cpu_params_[i]->Data(), server_cpu_params_[i]->Dim(),
MPI_FLOAT, worker_rank, kTagModel,
worker_cpu_params_[i]->Data(), worker_cpu_params_[i]->Dim(),
MPI_FLOAT, worker_rank, kTagModel,
MPI_COMM_WORLD, &status);
}
// 3. copy worker_cpu_params_ to worker_gpu_params_
for (int i = 0; i < worker_gpu_params_.size(); i++) {
worker_gpu_params_[i]->CopyFromVec(*worker_cpu_params_[i]);
}
// 4. update server gpu model
for (int i = 0; i < server_gpu_params_.size(); i++) {
//x_server = x_server + alpha(x_worker - x_server)
// = (1 - alpha) * x_server + alpha * x_worker
server_gpu_params_[i]->AddVec(alpha_, *worker_gpu_params_[i], 1 - alpha_);
}
}
Worker Code
bool EasgdWorker::Synchronize(int num_worker_samples) {
(void)num_worker_samples;
int msg_type = kMsgSynchronize;
// 1. send synchronize signal
MPI_Send(&msg_type, 1, MPI_INT, MainNode(), kTagMsg, MPI_COMM_WORLD);
// 2.1 copy worker_gpu_params_ to worker_cpu_params_
for (int i = 0; i < worker_gpu_params_.size(); i++) {
worker_cpu_params_[i]->CopyFromVec(*worker_gpu_params_[i]);
}
// 2.2 send woker_cpu_params_ and recv server_cpu_params_
MPI_Status status;
for (int i = 0; i < server_cpu_params_.size(); i++) {
MPI_Sendrecv(worker_cpu_params_[i]->Data(), worker_cpu_params_[i]->Dim(),
MPI_FLOAT, MainNode(), kTagModel,
server_cpu_params_[i]->Data(), server_cpu_params_[i]->Dim(),
MPI_FLOAT, MainNode(), kTagModel,
MPI_COMM_WORLD, &status);
}
// 2.3 copy server_gpu_params_ to server_cpu_params_
for (int i = 0; i < server_gpu_params_.size(); i++) {
server_gpu_params_[i]->CopyFromVec(*server_cpu_params_[i]);
}
// 2.4 update worker gpu model
for (int i = 0; i < worker_gpu_params_.size(); i++) {
worker_gpu_params_[i]->AddVec(alpha_, *server_gpu_params_[i], 1 - alpha_);
}
// always return ture
return true;
}
BMUF(Block Momentum Update Filtering)
微软的BMUF在形式上与EASGD比较类似,但有两个显著不同点:
- BMUF中worker在每次同步更新之后,使用相同的global model作为本地初始模型,在该模型上迭代。
- BMUF使用momentum
BMUF Algorithm

Worker Code
bool BmufWorker::Synchronize(int num_worker_samples) {
int num_all_samples = num_worker_samples;
AllReduce(&num_all_samples, 1);
// All workers finished it's data, return instantly
if (num_all_samples <= 0) {
KALDI_LOG << "All worker finished their data";
return false;
}
// Do BMUF(Block Momentum Update Filtering)
for (int i = 0; i < gpu_params_.size(); i++) {
// 1. calc grad w(t) - wg(t-1)
grad_gpu_params_[i]->CopyFromVec(*gpu_params_[i]);
grad_gpu_params_[i]->AddVec(-1.0, *prev_gpu_params_[i]);
grad_cpu_params_[i]->CopyFromVec(*grad_gpu_params_[i]);
// 2. reduce
AllReduce(grad_cpu_params_[i]->Data(), grad_cpu_params_[i]->Dim());
// 3. copy to gpu
grad_gpu_params_[i]->CopyFromVec(*grad_cpu_params_[i]);
// 4. calc mometum grad: d(t) = m * g(t-1) + (1 - m) * lr * g(t)
float lr = (1.0 - momentum_) * learn_rate_;
grad_gpu_params_[i]->AddVec(momentum_, *prev_grad_gpu_params_[i], lr);
// 5. update model w(t) = w(t-1) + d(t)
gpu_params_[i]->CopyFromVec(*prev_gpu_params_[i]);
gpu_params_[i]->AddVec(1.0, *grad_gpu_params_[i]);
// 6. update prev
prev_gpu_params_[i]->CopyFromVec(*gpu_params_[i]);
prev_grad_gpu_params_[i]->CopyFromVec(*grad_gpu_params_[i]);
}
return true;
}