- 参考书籍
- Basic Text Processing
- Edit Distance
- Language Modeling
- Spelling Correction
- Text Classification
- Sentiment Anylasis
- Discriminative classifiers: Maximum Entropy classifiers
- Pos Tagging词性标注
参考书籍
- 朱拉夫斯基和曼宁《语音与语言处理》
- 曼宁、舒策、拉哈万《信息检索导论》(2008)
- 伯德、克莱因、洛普《使用Python进行自然语言处理》(2009)
- 做实验的数据可以在Peter Norvig查找
Basic Text Processing
Regular Expression
- []: [wW]oodchuck, [0-9], [a-z]
- ’[^]: not, [\^a-z]’
- |: or
- ?, *, +, .: times
- ^, &: start & end
Word Tokenization
shakespeare
tr -sc 'a-zA-Z' '\n' < shakespeare.txt | sort | uniq -c | sort -n -r | less
- 将非单词替换为\n
- 排序
- 去重,并统计出现次数, uniq -c
- 按出现次数排序,逆序输出
- 如何统计每个单词的重复出现次数
tr -s "\t| " "\n" < word.txt | sort | uniq -c
中文的分词
- max-match, 最大前向匹配
- 最大后向匹配
- 语言模型结合viterbi算法打分
Word Normaliztion & Stemming
- stem: Porter’s algorithm
- affix
Sentence Segmentation
- ?, !: 通常没有歧义
- .: 存在歧义,如Dr. 2014.12等。 解决方法,使用决策树判断.是否为句子结束
Edit Distance
- Levenshtein distance: 替换代价为2,可以理解为先删除再插入
- 算法: 动态规划, 通过回溯二维数组pre[i,j] = DOWN, LEFT, DIAG来记录回溯信息
- 加权Edit Distance
- confusion matrix, a容易被拼写为e;
- 物理键盘的布局


Language Modeling
理论 & 应用
- 机器翻译, Spell Correction, 语音识别
- 一些工具 SRILM, Google N-Gram Release
- a) Markov假设, b)取log避免下溢
Perplexity,如何评价一个语言模型
- P[P(W)] = P(W)^1/N, 取对数即为1/NlogP(W)
- Perplexity越小,better model
数据稀疏
测试数据中出现训练集不存在的语法怎么办?
- Add-One Smoothing V个人感觉应为所有uigram即单词个数,不论是几元文法
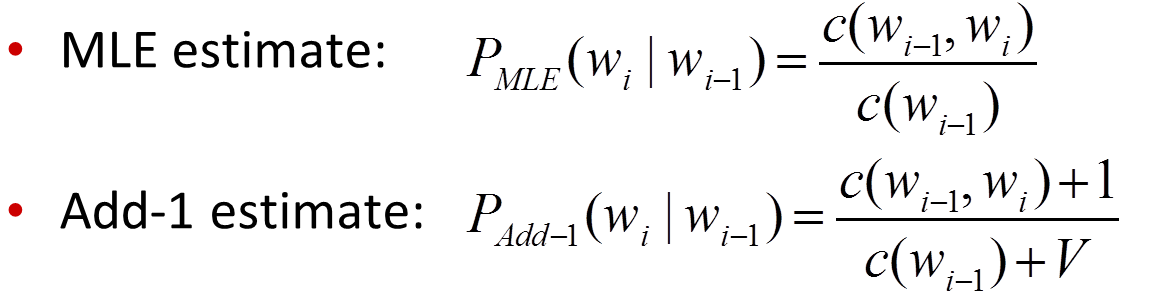
在V » c(wi-1)时,即训练语料库中绝大部分n-gram未出现的情况(一般都是如此),Add-one Smoothing后有些“喧宾夺主”的现象,效果不佳。 所以n-gram中一般不使用,但在文本分类中使用
- Good-Turing Estimate(参考数学之美)
- 一般来说,出现一次的词的数量比出现两次的多,出现两次的比出现三次的多。这种定律成为Zipf定律。
- 基本思想是利用频率的类别信息对频率进行平滑。调整出现频率为c的n-gram频率
- 改进策略就是“对出现次数超过某个阈值的gram,不进行平滑,阈值一般取8~10”
- 估计P_{0},就得先统计N_{0}
- Stupid Backoff
思想很简单找得到直接mle,找不到回退,乘以0.4作为惩罚。 如计算bigram如下若该bigram存在,则直接计算score,不存在则回退计算其unigram score, 0.4作为惩罚因子。
``` python
def score(self, sentence):
""" Takes a list of strings as argument and returns the log-probability
of the sentence using your language model. Use whatever data you
computed in train() here."""
score = 0.0
previous = sentence[0]
for token in sentence[1:]:
bicount = self.bigramCounts[(previous, token)]
bi_unicount = self.unigramCounts[previous]
unicount = self.unigramCounts[token]
if bicount > 0:
score += math.log(bicount)
score -= math.log(bi_unicount)
else:
score += math.log(0.4)
score += math.log(unicount + 1)
score -= math.log(self.total + self.vocab_size)
previous = token
return score
```
Spelling Correction
拼写错误
据统计,80%的拼写错误编辑距离为1,几乎所有的拼写错误编辑距离小于等于2 Kukich(1992)指出有25%~40%的拼写错误都属于Real-word类型
- 拼写错误类型,Non-word和Real-word(虽然拼写错误,但仍出现在词典中)
- $w = arg max P(x|w)P(w)$, 前者为channel(error) model, 后者为language model, 可以使用unigram, bigram and on
- $P(x|w)$ 中包含了transpose error,confusion matrix
如何写一个拼写检查器
- 根据编辑距离对x生成候选集合$w$, 并计算P(x|w)
- 选择语言模型(unigram | bigram | …)
- $w = arg max P(x|w)P(w)$
Peter Norvig Corrector
参考How to Write a Spelling Corrector,这段代码非常简洁优美。
import re, collections
def words(text): return re.findall('[a-z]+', text.lower())
def train(features):
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
NWORDS = train(words(file('big.txt').read()))
alphabet = 'abcdefghijklmnopqrstuvwxyz'
def edits1(word):
n = len(word)
return set([word[0:i]+word[i+1:] for i in range(n)] + # deletion
[word[0:i]+word[i+1]+word[i]+word[i+2:] for i in range(n-1)] + # transposition
[word[0:i]+c+word[i+1:] for i in range(n) for c in alphabet] + # alteration
[word[0:i]+c+word[i:] for i in range(n+1) for c in alphabet]) # insertion
def known_edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS)
def known(words): return set(w for w in words if w in NWORDS)
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word]
return max(candidates, key=lambda w: NWORDS[w])
if __name__ == '__main__':
while True:
print correct(raw_input(">"))
Text Classification
方法(Naive Bayes, SVM)
Naive Bayes
基本和原来机器学习时内容一致,几个在实践时需要关注的问题
- 取log,避免下溢
- Add-One Smoothing
- 频率为统计频率,not boolean freqency
Sentiment Anylasis
Also Opnion Extraction, Opnion Mining, Sentiment Mining, Subjectivity Anylasis
Steps
- tokenize
- Feature Extraction
- 分类器,这里分类器可以使用Naive Bayes, Svm, MatEnt等,后两者效果要好。
Naive Bayes in Sentiment
主题仅与词出现有关系,和出现次数关系不大。所以这里使用Boolean Multinomial Naive Bayes(Mutivariate Benoulli Naive Bayes), 即贝努利频率,相应的Add-one方法更改为Add-delta \(P(w|c) = \frac{n_{k}+\alpha} {n+\alpha|V|}\)
情感词典
成熟开放的情感词典
- GI(The General Inquirer)
- LIWC (Linguistic Inquiry and Word Count)
- …
Learning Sentiment Lexicons
- 利用and和but连接词的词性关系(这个想法很棒)
Discriminative classifiers: Maximum Entropy classifiers
生成模型 & 判别模型
判别方法:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。典型的判别模型包括k近邻,感知级,决策树,支持向量机等。 生成方法:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。基本思想是首先建立样本的联合概率概率密度模型P(X,Y),然后再得到后验概率P(Y|X),再利用它进行分类
Pos Tagging词性标注
Homework
- regular expression
- autocorrect(edit distance, language model)
- test
不同点有两处,一是形参用逗号直接求值,形式体则用逗号和@ 即 “,@” 去掉对形式体求值后所得到的表达式最外层列表的括号,将这个表达式嵌入到最外围列表的最后面;二是形参要做一系列处理,而形式体则直接求值嵌入,不做任何变化,这是因为这个形式体本来就是新宏的处理语句,定义宏只需要照搬即可,不需要也不应该做其他变化。
Everything should be made as simple as possible, but not any simpler