G2P Task
G2P在语音识别、语音合成、自然语音处理中都有着广泛的应用。 G2P的目标的是给定一个词,生成其发音音素序列。例如
PHONIX -> /f i n I k s/
例如在语音合成中,一般使用Phone label作为神经网络的输入,因此需要把词转换为其相应的音素序列,然后进行处理。 对于常见的词,可以在预先生成的词典中查找该词的phone发音,然而,当该词未在词典中出现时(OOV, Out Of Vocabulary),就需要对该词的发音phone进行预测。 例如英文中,人名、地名、实体名等中都会存在大量的OOV。
本文中介绍解决该问题的两种方法
- 基于传统方法的Phonetisaurus G2P
- 基于深度学习Sequence to Sequence方法的G2P
以上2种方法均在训练阶段使用标注的数据训练模型,在inference时使用预先训练的模型对发音做预测。
Phonetisaurus G2P
Phonetisaurus is suitable for training, evaluating and using grapheme-to-phoneme models for speech recognition using the OpenFst framework.
Phonetisaurus是一个基于Openfst框架的G2P工具。它将G2P的问题分成以下3个字问题。
- 对齐问题。自动对单词的Character序列和Phone序列进行对齐,即找到哪些Character对应的是哪个发音。例如在PHONIX中PH->f, O->i, N->n, I->I, X->{k,s}
- 训练问题。利用1中的方法对训练词典中所有的词生成对齐,然后训练一个joint sequence的ngram model.
- 解码问题。利用训练好的模型预测输入词的Phone Sequence。
对齐问题
在本文中考虑character到phone的one-to-many和many-to-one的映射关系。例如:
- many-to-one: sh - [ S ], ph - [ f ]
- one-to-many: x - [ k s ], u - [ j u ]
考虑实际情况,many的时候均有最大长度限制(感觉上一般为2或者3)。 此外还需考虑到insertion与deletion,例如hour中h不发音。
将一个单词character序列与其对应的phone序列满足上述条件的各种组合展开。考虑最简单的one-to-one的情况, 以fix -> /f I k s/为例,则可能的对齐有(@左边为character,右边为phone,_表示空):
- _@f i@I i@k x@s
- f@f _@I i@k x@s
- f@f i@I _@k x@s
- f@f i@I x@k _@s
所有的对齐可以通过fst表示为lattice的形式,如下图所示:
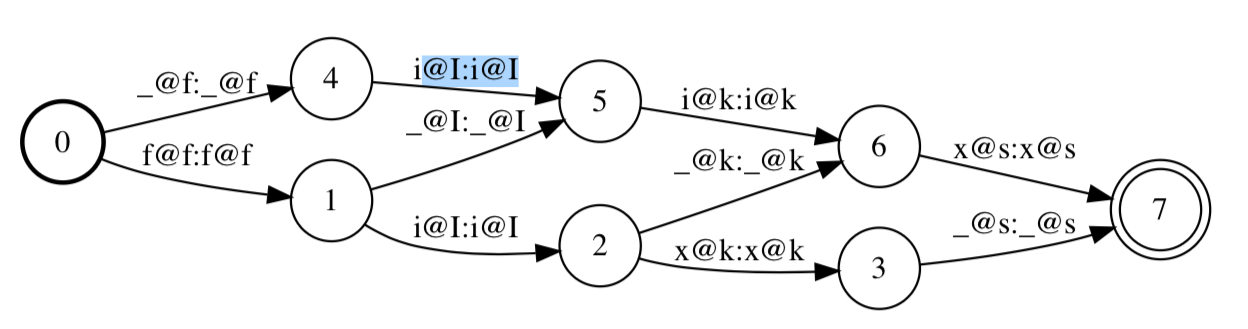
假设character->phone的映射满足一定概率,则每条边上的的映射则通过概率引入权重,lattice即转换为WFST,那么最有可能的对齐序列可以通过FST的最短路径算法得到。
那么如何得到character->phone映射概率呢?我们可以通过前向后向算法和EM算法在整个词典上的数据集上进行估计。
- 对词典中所有的词生成可能对齐的fst lattice表示。
- 对所有可能的character->phone的映射组合进行概率初始化,并将初始值代入每个FST中。
- E步:利用前向后向算法,计算每个FST中每条边上的概率(即每个词中character->phone概率的局部估计)。
- M步:利用所有词的局部估计对所有character->phone的概率进行更新,并带入FST lattice中。
- 重复3,4直至满足一定条件。
其中,E步和M步的一些细节,包括论文中的一些公式,看的不是很懂,就不详细展开了。
其实,到这里时,我们可以拿到所有character->phone的映射的概率,对于任意一个新词,我们可以生成该词对应的fst lattice表示,代入每个character->phone的概率,使用fst最短路径算法,即可以得到该词的phone sequence。这样的缺点是仅仅孤立考虑了每个character->phone的映射概率,并没有考虑到其上下文。假设能在建模时引入发音的上下文,则可以得到更为精确的G2P模型,由此引出训练问题。
训练问题
Phonetisaurus中通过ngram对上下文建模。具体做法如下:
- 将词典中所有词的对齐转换为joint align pair,例如对fix有f@f i@I x@{k,s}。
- 利用1中所有词的joint align训练ngram。
- 将ngram转为WFST表示。
解码问题
在ngram G2P模型上直接做最短路径的搜索即可。
Usage
# Prepare data
wget https://raw.githubusercontent.com/cmusphinx/cmudict/master/cmudict.dict
cat cmudict.dict \
| perl -pe 's/\([0-9]+\)//;
s/\s+/ /g; s/^\s+//;
s/\s+$//; @_ = split (/\s+/);
$w = shift (@_);
$_ = $w."\t".join (" ", @_)."\n";' \
> cmudict.formatted.dict
# Align the dictionary (5m-10m)
phonetisaurus-align --input=cmudict.formatted.dict \
--ofile=cmudict.formatted.corpus --seq1_del=false
# Train an n-gram model (5s-10s):
ngram-count -kndiscount -order 8 -text cmudict.formatted.corpus \
-lm cmudict.o8.arpa
# Convert to OpenFst format (10s-20s):
phonetisaurus-arpa2wfst --lm=cmudict.o8.arpa --ofile=cmudict.o8.fst
# Test
phonetisaurus-g2pfst --nbest=1 --model=cmudict.o8.fst --wordlist=test.wlist
Sequence to Sequence
G2P可以看作是把Character的序列转为Phone的序列,也就是一个Sequence to Sequence的任务。用当下流行的深度学习技术,也可以直接解决该问题。g2p-seq2seq中实现了一个基于Transformer的G2P。
中文G2P
在中文中,若G2P的输入为汉字,输出为音节syllable,即input和output存在一一对应的关系,则可以使用CRF,即序列标注的方式做中文G2P。
Reference
- WFST-based Grapheme-to-Phoneme Conversion: Open Source Tools for Alignment, Model-Building and Decoding
- g2p-seq2seq